L’integrazione tra Proxmox Virtual Environment (PVE) e Veeam Backup & Replication (VBR) rappresenta un passo significativo per ottimizzare le politiche di backup e recupero. Questo articolo illustra i passaggi chiave per abilitare il plug-in di VBR, a partire dall’architettura del sistema, fino all’installazione e configurazione del plug-in, e all’aggiunta del server Proxmox nella console di VBR.
Si noti che le istruzioni si basano sulla versione Beta del plug-in, pertanto potrebbero esserci differenze nella versione ufficiale.
Rileggendo l’articolo scritto qualche mese fa (disponibile su questo sito al seguente link), credo che chi considera la virtualizzazione una commodity sceglierà PVE per uscire rapidamente dall’incertezza causata dalle scelte commerciali di Broadcom.
Nota 1: PVE è una distribuzione Linux basata su Debian con kernel Ubuntu che consente l’implementazione e la gestione sia di macchine virtuali che di container.
Nota 2: Proxmox è un’azienda Europea con sede in Austria.
In questo primo articolo (di tre) vedremo i passaggi fondamentali per abilitare il plug-in che permette a VBR di realizzare politiche di backup e ripristino.
Chiedete al vostro Veeam SE di riferimento per testare la versione Beta.
Architettura:
L’immagine 1 riporta lo schema di funzionamento dell’integrazione. Il Plug-in è il componente che abilita la comunicazione tra il Backup Server Veeam (VBR) e l’architettura Proxmox.
Nota 3: Il ruolo Proxy (qui denominato Worker) ha il compito di raccogliere i dati delle VM da proteggere per copiarli verso il Backup Repository.
Il processo di Backup prevede l’innesco di snapshot e la connessione tra il server Proxmox e VBR avviene tramite API REST.
Immagine 1
Una volta installato il plug-in sul server VBR è necessario:
Dalla consone di VBR all voce Backup Infrastructure aggiungere il server Proxmox (immagine 2 e 3).
Immagine 2
Immagine 3
2. Nelle successivle immagini (dalla 4 alla 9) sono mostrati i semplici passaggi per aggiungere l’architettura PVE nella console di VBR.
Immagine 4
Immagine 5
Immagine 6
Immagine 7
Nota 4: E’ possibile selezionare lo storage ove le snapshot verranno salvate.
Immagine 8
Immagine 9
Al termine è possibile effettuare immediatamente il deploy del worker (proxy). Il vantaggio è quello di accelerare il processo di backup (immagine 10).
Immagine 10
Nota 5: Per chi proviene dal mondo VMware è esattamente come abilitare il metodo di trasporto virtual appliance.
In quest’ultima fase è possibile configurare su quale host effettuare il deploy del worker, quale storage utilizzare (immagine 11), quali risorse assegnare (immagine 12) e su quali reti operare (immagine 13, 14 e 15 ).
Immagine 11
Immagine 12
Immagine 13
Immagine 14
Immagine 15
Dopo aver controllato che tutte le configurazioni soddisfino le desiderate (immagine 16), cliccando su finish il setup è completato.
Immagine 16
Nel prossimo articolo vedremo come configurare i job di Backup.
Immaginate un disastro, in cui l’infrastruttura virtuale deve essere ripristinata da zero.
È tutto perso, tranne i file di backup, che sono ancora disponibili su almeno un repository, meglio se immutabile, on-premises o in cloud.
Per ripristinare l’ambiente avete a disposizione cinque differenti opzioni che sono in funzione da come è stata disegnata e implementata l’architettura di protezione e resilenza Veeam Backup & Replication.
Nota 1: Veeam Backup & Replication verrà d’ora in avanti indicato con l’acronimo VBR.
Scenario A (Ripristino da zero):
Non avete effettuato il backup application aware del server VBR.
Non avete effettuato la Replica application aware del server VBR.
Non è disponibile l’export della configurazione del DB del server VBR.
Volete ripristinare immediatamente i workload di produzione.
In questo passaggio è spesso sufficiente cliccare solo su “next” per completare l’operazione.
Nota 3: si consiglia di utilizzare il proprio file di licenza (può essere scaricato da my.veeam.com) anche se la Community Edition (senza licenza) è spesso sufficiente per la maggior parte ripristini necessari in questa fase.
Passaggio 2A: Aggiungere l’infrastruttura virtuale di produzione ove si voglia ripristinare i carichi di lavoro protetti da VBR.
Come: dopo aver completato il primo passaggio, dalla console di VBR aggiungete l’infrastruttura virtuale (Menù: “Inventory” -> “Vmware vSphere“-> “Add Server”) (Immagine 2).
Immagine 2
I passaggi seguenti dipendono dalla tipologia di Hypervisor (VMware vSphere, Microsoft Hyper-V, Nutanix AHV, …) ma risultano sempre molto semplici.
Passaggio 3A (opzionale): Aggiungere i proxy di backup.
Anche se stiamo operando a livello di ripristino, è sempre una buona idea per migliorare le prestazioni di aggiungere proxy di backup.
Passaggio 4A: Aggiunta dei repository di backup Veeam.
L’ultima fase propedeutica prima di avviare i ripristini è quella di aggiungere i repository con i dati di backup.
Come: dalla console selezionare la voce “Backup Infrastructure”, “Backup Repository” e quindi “Add Repository” (immagine 3).
Immagine 3
Passaggio 5A: Avvio dei ripristini.
Come: dalla console di VBR selezionare dalla voce “Home”, “Backup”, “Disk imported”, la VM che si vuole ripristinare e cliccando con il tasto destro del mouse avviare il processo di ripristino (Immagine 4).
Immagine 4
Nota 4: Il ripristino può essere istantaneo. Con questa modalità le VMs sono avviate direttamente dal repository di backup. In questa opzione il repository funge da archivio dati (per VMware il DataStore) per l’ambiente virtuale.
(L’instant VM recovery è stato inventato da Veeam più di dieci anni fa e da allora ne ha migliorato performance e flessibilità).
Ora la vostra architettura di produzione è tornata operativa!
Nota 5: Esiste anche l’opzione di Extract da linea di comando per piattaforme Windows e Linux.
Passaggio 2B: Avviare l’Extract, selezionare il backup del VBR e una volta creati i file della VM-VBR copiateli nel Datastore VMware che preferite.
Ora dal vCenter registrate la VM appena copiata.
(Immagine 6)
Nota 6: E’ disponibile l’opzione di extract da linea di comando per piattaforme Windows e Linux.
Nota 7: E’ possibile automatizzare e semplificare la copia verso il Datastore VMware pubblicando una share di rete NFS come indicato nel seguente articolo:
Passaggio 3C: Una volta completato il ripristino del passaggio 2C, avviare il VBR e realizzare le operazioni standard di ripristino come indicato nel passaggio 5A.
Scenario D: Il VBR è una VM replicata.
Non avete effettuato il backup application aware del server VBR.
Avete effettuato la Replica application aware del server VBR.
Non è disponibile l’export della configurazione del DB del server VBR.
Volete ripristinare immediatamente il server VBR.
Cosa fare?
Passaggio 1D: Connettersi al vCenter e ricercare il VBR già replicato.
Immagine 9
Passaggio 2D: Innescare il failover del VBR.
Immagine 10
Passaggio 3D: Realizzare le operazioni di gestione di VBR come da punto 5A.
Scenario E: La configurazione del VBR.
Non avete effettuato il backup del server VBR.
Non avete effettuato la Replica del server VBR.
E’ disponibile l’export della configurazione del DB del server VBR.
Volete ripristinare immediatamente il server VBR.
Cosa fare?
Passaggio 1E: Installare VBR sul server (fisico o virtuale, vedi punto 1A).
Passaggio 2D: Effettuare il ripristino della configurazione del VBR come indicato nella guida.
Passaggio 3D: Realizzare le operazioni di gestione di VBR come da punto 5A.
Nota 8: E’ sempre buona norma salvare la configurazione del server di Backup.
Nota Finale: Il consiglio è di adoperarsi al fine di poter utilizzare tutte le strategie descritte in questo articolo in modo che se una non fosse disponibile, si possa utilizzarne una seconda.
Nel precedente articolo abbiamo visto come operare sui job di backup per ottenere dei Full che possano essere utilizzati per creare una politica di retention GFS quando la destinazione dei job è un nastro.
In questo secondo articolo, scopriamo come sia possibile ottenere un risultato simile copiando i nastri.
Nota1: Per perseguire questa processo di protezione è necessario che nel DataCenter sia presente una seconda libreria a nastro.
Nota2: Il caso d’uso più comune per il Copy-Tape è quello di migrare i dati contenuti sui nastri di una vecchia tecnologia (LT06) verso una nuova (LTO9), visto che la nuova tecnologia non sarebbe in grado di leggere nativamente i dati contenuti sui vecchi nastri.
Le fasi che ci permetteranno di raggiungere il nostro scopo sono due:
Fase 1: creazione di un pool di nastri afferente alla seconda libreria.
Fase 2: job di copia del tape.
Fase 1
La creazione del Media Pool (immagine 1), dovrà essere personalizzato impostando:
L’utilizzo di un nuovo nastro per ogni sessione di copia (immagine 2).
Impostazione di una retention che per quel gruppo di nastri coincida con quella richiesta dalla politica GFS (immagine 3).
Immagine 1
Immagine 2
Immagine 3
Nota3: Nell’immagine 3 è stata impostata una retention di 4 settimane che risponde alla necessità di tenere il full settimanale per 1 mese.
Nota4: L’immagine 4 evidenzia la possibilità di realizzare una politica di Vault per l’archiviazione dei nastri.
Immagine 4
FASE 2
Dall’interfaccia grafica di VBR selezionando con il tastro destro del mouse il nastro da copiare (immagine 5) è possibile avviare il comando di copia.
Immagine 5
I semplici passaggi successivi mostrati dalle immagini 6,7,8 e 9 mostrano come completare l’operazione di copia.
Immagine 6
Immagine 7
Immagine 8
Immagine 9
Ultime note:
La documentazione alla quale fare riferimento per conoscere quante risorse è indispensabile assegnare ai vari componenti è disponibile al seguente link.
Nel mio laboratorio è presente un server Ubuntu 22.04.4 LTS, sul quale è installato il software Veeam di protezione degli ambienti Salesforce (Veeam Backup for Salesforce).
Durante l’operazione mensile di aggiornamento del sistema operativo, sono apparsi alcuni errori che non mi hanno permesso il completamento dell’operazione.
L’ output del comando “sudo apt update”, mostrava tre errori evidenziati nell’immagine 1 con le frecce di colore blue, verde e rosso.
Immagine 1
1. Il primo, (freccia blue) indicava che la firma digitale legata al repository Veeam (“https://repository.veeam.com/apt stable/amd64/ In Release”) non fosse più valida.
2. Il secondo (freccia verde) indicava che anche per il sito Ubuntu-security (“http://security.ubuntu.com/ubuntu bionic-security InRelease”) la firma digitale fosse scaduta.
3. Il terzo errore (nella realtà un warning, freccia rossa), indicava che la metodologia di gestione delle chiavi denominata “apt-key” è deprecata consigliando l’ utilizzo di un metodo più sicuro denominato “trusted.gpg.d”.
—
Navigando su internet ho trovato le soluzioni che hanno risposto alle mie necessità:
1. Sul sito Veeam è presente la KB2654 che indica come importare una nuova chiave. L’unica vera attenzione è avviare il comando da utente root (vedi immagine 2).
Immagine 2
2. Come mostrato nell’ immagine 3, è sufficiente richiedere l’aggiornamento della chiave inserendo a fine comando l’identificativo richiesto nell’output dell’immagine 1 (freccia verde).
immagine 3
Nota 1: apt-key è un comado utilizzato per gestire un portachiavi di chiavi gpg per apt sicuro. Il portachiavi è conservato nel file ‘/etc/apt/trusted.gpg’ (da non confondere con il correlato ma non molto interessante /etc/apt/trustdb.gpg). Il comando apt-key può essere utilizzato per mostrare le chiavi nel portachiavi e per aggiungere o rimuovere le chiavi.
3. Nell’ultima riga dell’immagine 4 viene indicato il comando che indirizza il warning di sicurezza. Si tratta di copiare il portachiavi (trusted.gpg) all’interno della cartella trusted.gpg.d.
Immagine 4
Nell’articolo “Handeling the apt-key deprecation” trovete tutti i dettagli che illustrano i vantaggi in ambito di sicurezza del nuovo approccio.
Molti clienti e partner chiedono se sia possibile implementare una politica di protezione di tipo GFS (Grandfather – Father – Son), quando i dati da proteggere afferiscono ad una NAS (Network Attacched Storage) e la destinazione è una libreria a nastri.
Tale automatismo con la versione attuale di Veeam Backup & Replication (VBR) 12.1 non è ancora disponibile, cosa invece è già possibile effettuare quando la sorgente del dato è un backup di VM e Server Fisici.
In questo primo articolo vi aiuterò a raggiungere l’obiettivo, sfruttando la grande flessibilità di VBR nella creazione dei job di backup.
Nota1: Nel prossimo vi illustrerò come realizzare copie GFS sfruttando una funzionalità poco conosciuta di VBR, il Tape Copy.
Flessibilità dei Job di Backup:
a.VBR gestisce i nastri utilizzando un architettura che si basa su:
Media Pool (MP) sono i contenitori logici dei nastri e possono afferire ad uno o più job di Backup (nel nostro scenario creeremo un MP per Job).
Media Set (MS) identifica i restore point presenti sul nastro (nel nostro scenario creeremo un MS per job di Backup per singolo nastro).
b. La soluzione proprosta è quella di creare job di backup settimanali, mensili e annuali in modalità full. Tali backup dovranno essere creati in uno specifica data e i backup dovranno risiedere su pool di nastri creati all’uopo.
Vediamo step by step come procedere:
c.Creazione dei Media Pool (MP) settimanale e mensile
Immagine 1
Dall’immagine 2 è importante osservare che verrà utilizzato un nuovo nastro per ogni sessione di backup.
Immagine 2
Nell’immagine 3 è mostrato come impostare la retention che in questo scenario è di 4 settimane.
Immagine 3
Per il MP Mensile si utilizza la stessa procedura, modificando la retention in 12 mesi (vedi immagini 4,5,6).
Immagine 4
Immagine 5
Nell’immagine 6 si osserva che la retention per i Full Mensili è di 12 mesi.
Immagine 6
d. Creazione dei job di Backup
Immagine 7
immagine 8
L’immagine 9 evidenzia lo scheduling del job di Backup.
L’ipotesi è di realizzare n job di backup full per ogni politica GFS.
Nel nostro scenario di esempio è riportato il job della prima settimana (freccia blue) con retention settimanale (freccia verde). Per la seconda, terza e successiva settimana si procederà in modo del tutto analogo, sostituendo alla voce “Run the full backup automatically” il valore first con second, third ecc.
Immagine 9
L’immagine 10 evidenzia (freccia arancio) che non saranno avviati backup incrementali.
immagine 10
Gli stessi passaggi devono essere implementati per creare backup GFS di tipo mensile, nell’esempio ho impostato l’avvio del job di backup il 4 sabato del mese (immagine 12 – freccia blue).
Immagine 11
Immagine 12
Immagine 13
Nota 2:
Il licensing conteggia le licenze per singolo job di Backup (verisione 12.1).
Effettuate dei test per essere certi che lo scenario corrisponda alle vostre necessità. Fatevi aiutare dal supporto Veeam.
Nel prossimo articolo vedremo come utilizzare la funzionalità di Tape Copy.
Un articolo dedicato a come poter delegare i ripristini con Veeam Backup & Replication (VBR).
Il case study è legato alla protezione di file in cartelle condivise, ma può essere esteso a molti degli oggetti protetti con VBR. (vedi immagine 7)
—
Nell’immagine 1 sono illustrate le tre cartelle di rete condivise (SHARE-A, SHARE-B, SHARE-C) che sono utilizzate come sorgente dei file da proteggere.
Immagine 1
Nello scenario si ipotizza che per ogni singola cartella condivisa, solo uno specifico utente possa procedere alle attività di ripristino.
L’ immagine 2 evidenzia la creazione di tre utenti di Dominio, ShareA, ShareB, ShareC.
Immagine 2
I file afferenti ad una specifica cartella condivisa saranno ripristinabili dall’utente che ha nel nome l’identica lettera finale. Ad esempio, i file afferenti alla SHARE-A saranno ripristinabili dall’utente ShareA.
(NDR: Per semplicità espositiva la lettera X sostituirà una delle tre lettere dell’alfabeto A-B-C)
Per ogni cartella condivisa è stato creato un job di Backup denominato “BkF-Share-X”
L’immagine 3 evidenzia che il job “BKF-Share-A” (freccia arancio) protegge l’intera SHARE-A (freccia Blue).
Immagine 3
Nell’immagine 4 viene evidenziato il menù “configurazione” dall’ Enterprise Manager.
In questa fase di configurazione sono necessarie le credenziali amministrazione.
Immagine 4
Dal sotto menù role (immagine 5 – freccia arancio) vengono aggiunti (freccia verde) i tre utenti precedentemente creati (ShareX) ai quali viene assegnato il ruolo di Restore Operator (freccia blue).
Immagine 5
L’immagine 6 mostra le opzioni di delega.
All’ utente ShareA (freccia verde) viene assegnata la possibilità di effettuare il ripristino di tutti gli oggetti protetti da VBR attraverso il pulsante “Choose” (freccia arancio); nelle opzioni di ripristino è possibile permettere il solo ripristino in-place (freccia blue).
Nelle immagini successive (7-8) viene indicato come effettuare la scelta degli oggetti da visualizzare durante le operazioni di delega del ripristino.
Immagine 6
immagine 7
Immagine 8
L’immagine 9 illustra e conferma che effettuato il login dall’Enterprise Manager con le credenziali dell’utente ShareX (freccia Blue), siano visibili e ripristinabili solo i file della corrispettiva cartella condivisa (freccia arancio).
Immagine 9
Nota Finale:
La gestione degli utenti è configurabile attraverso i gruppi AD.
E’ possibile abilitare e disabilitare temporaneamente il ripristino di file ad un singolo utente o gruppi di utenti.
Il licensing conteggia la quantità di dati protetti per ogni singolo job di Backup. (Il NAS Pack ha lo scopo di rispondere alle necessità di grandi quantità di dati).

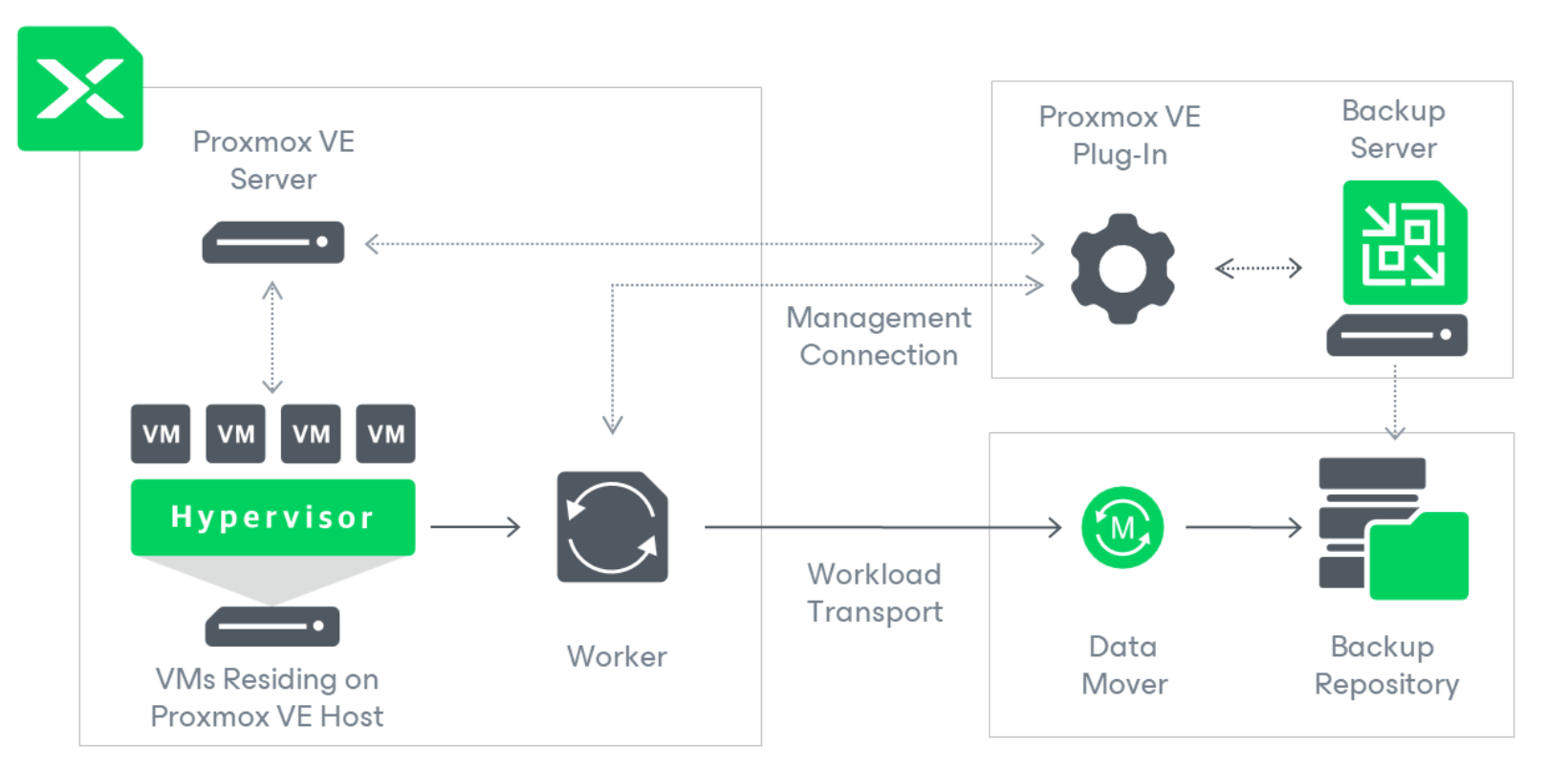 Immagine 1
Immagine 1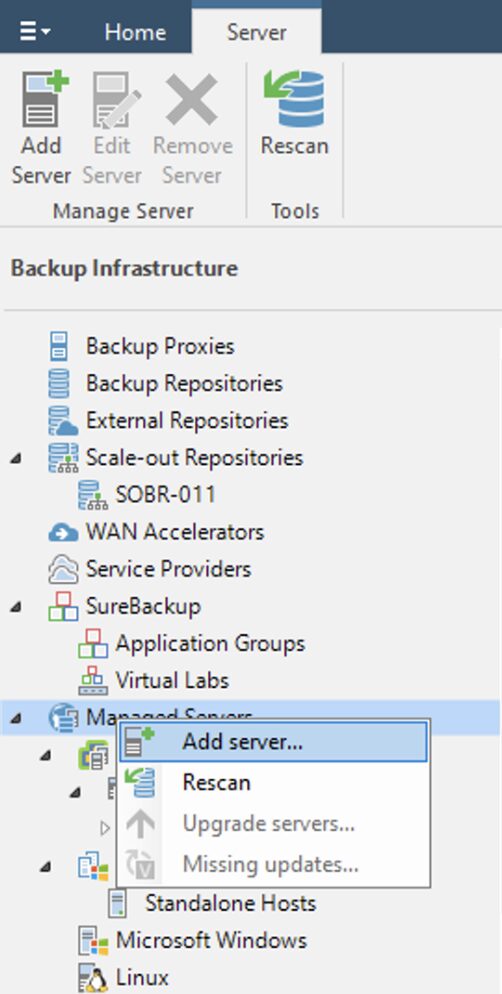 Immagine 2
Immagine 2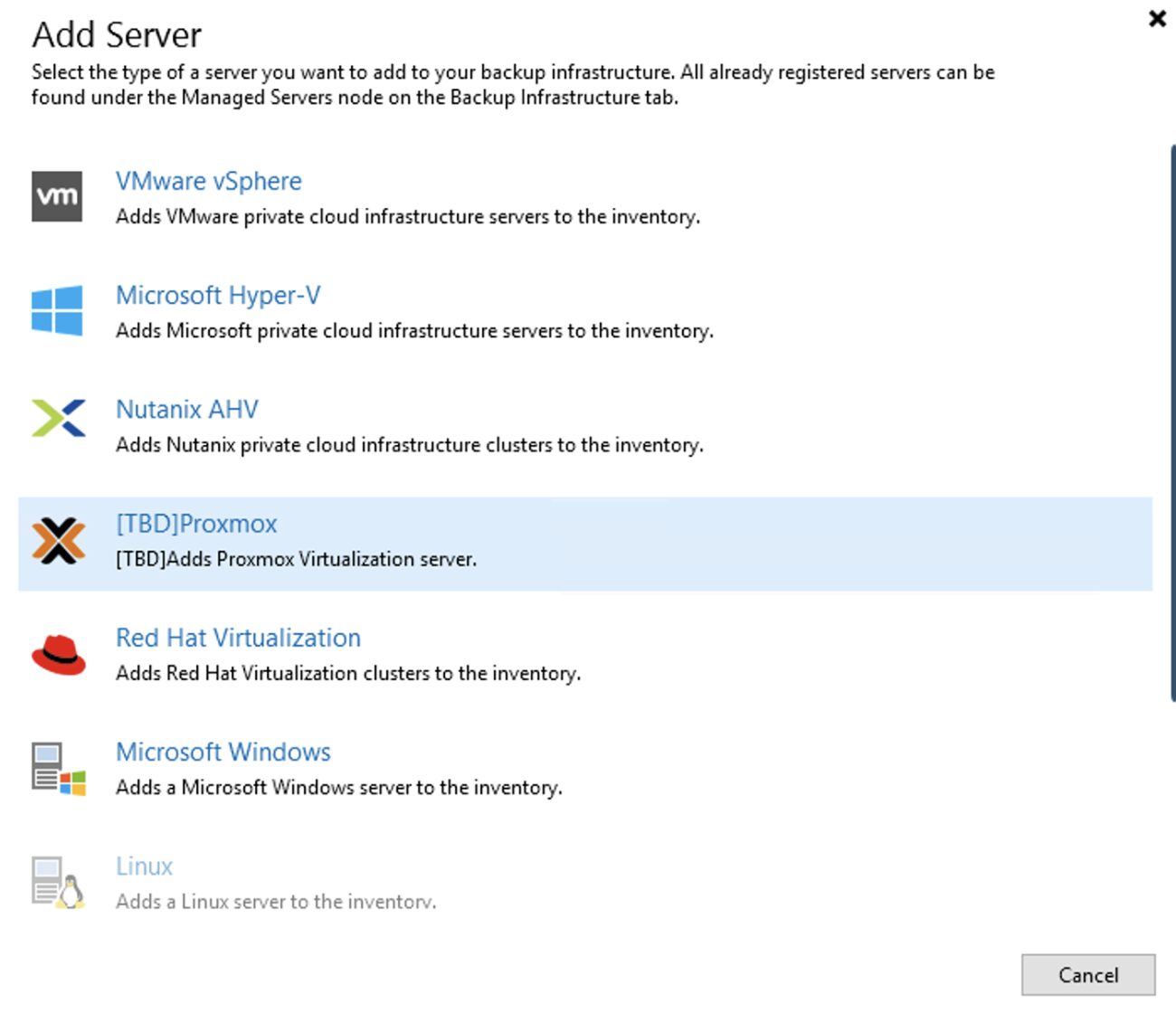 Immagine 3
Immagine 3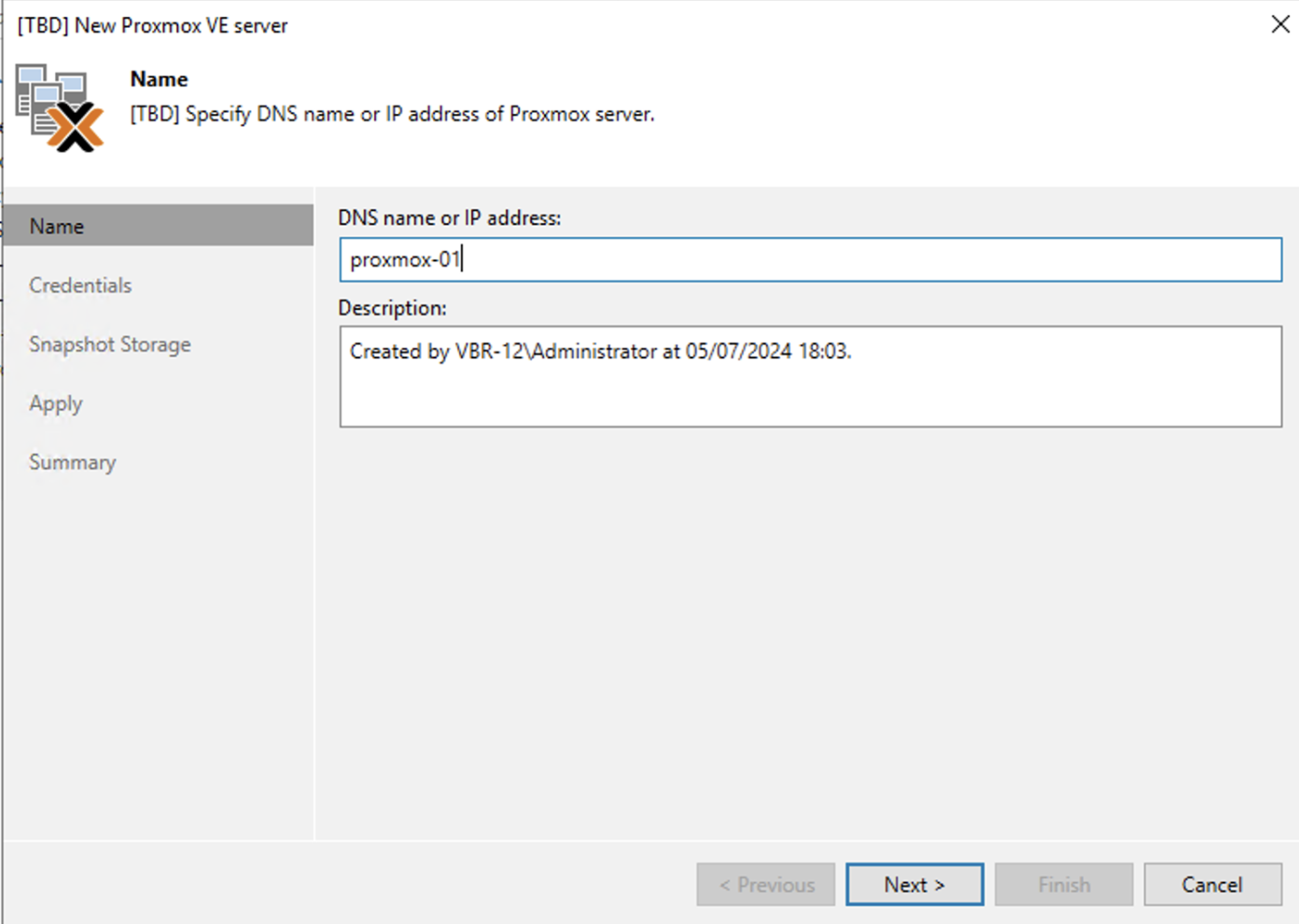 Immagine 4
Immagine 4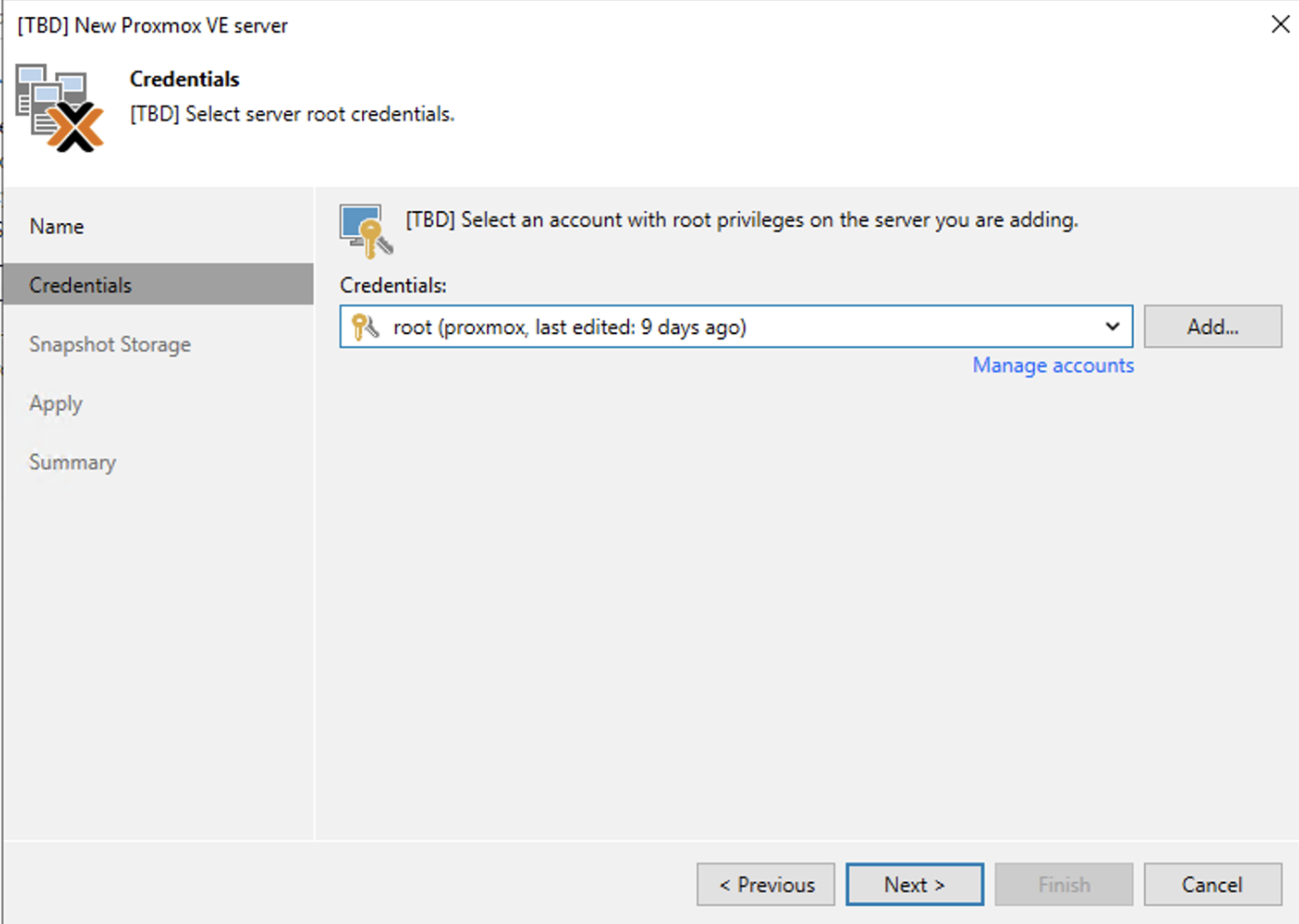 Immagine 5
Immagine 5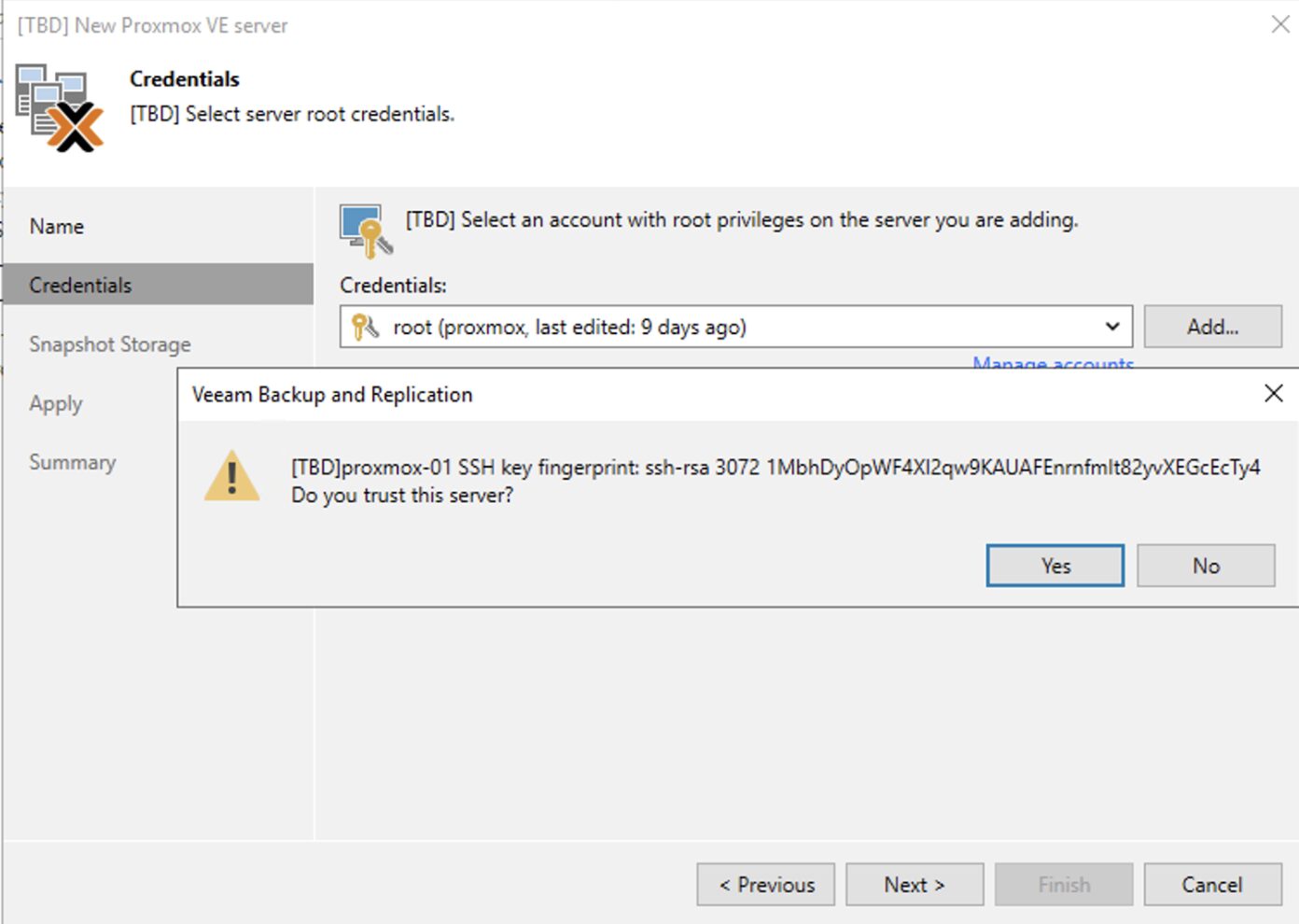 Immagine 6
Immagine 6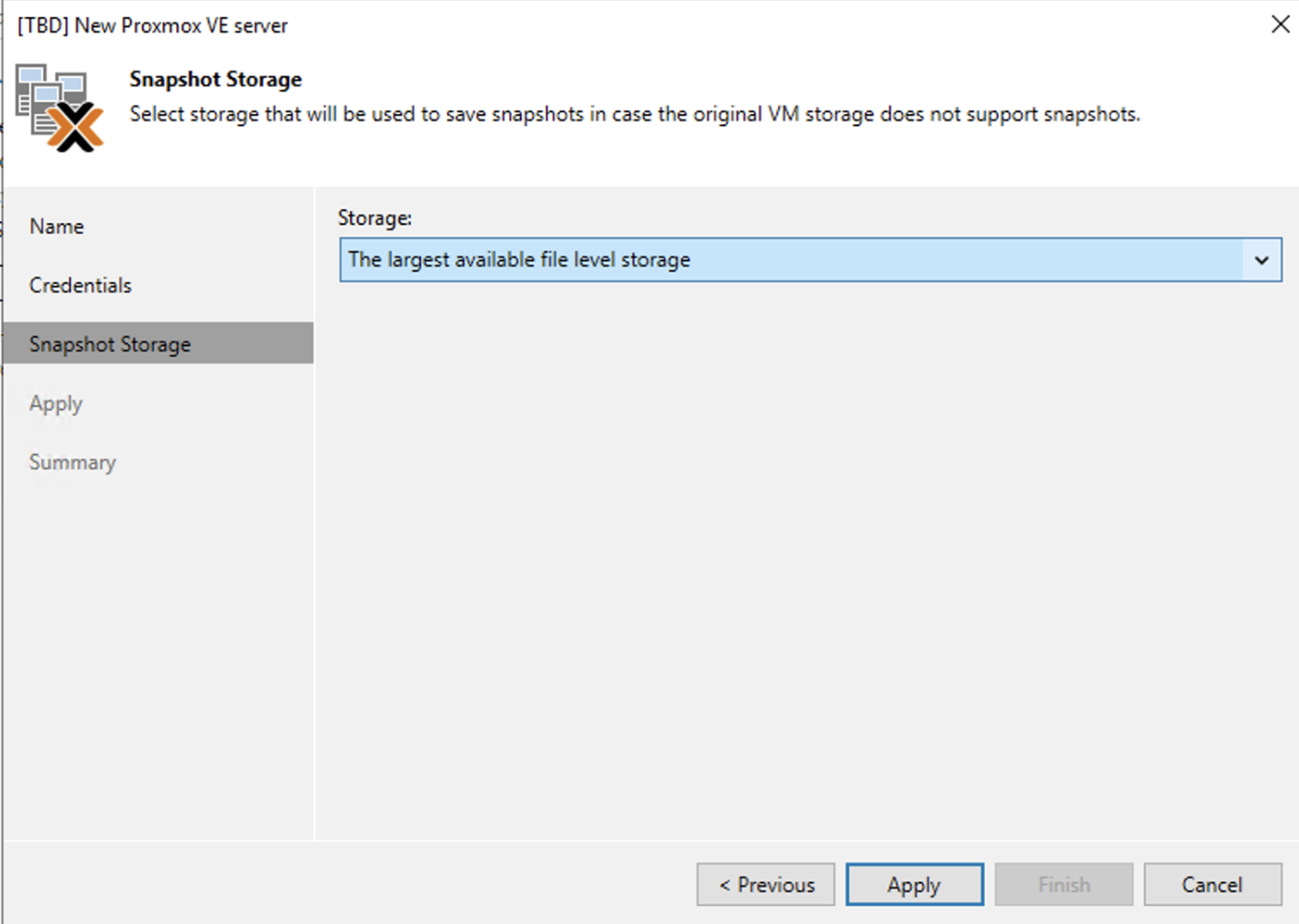 Immagine 7
Immagine 7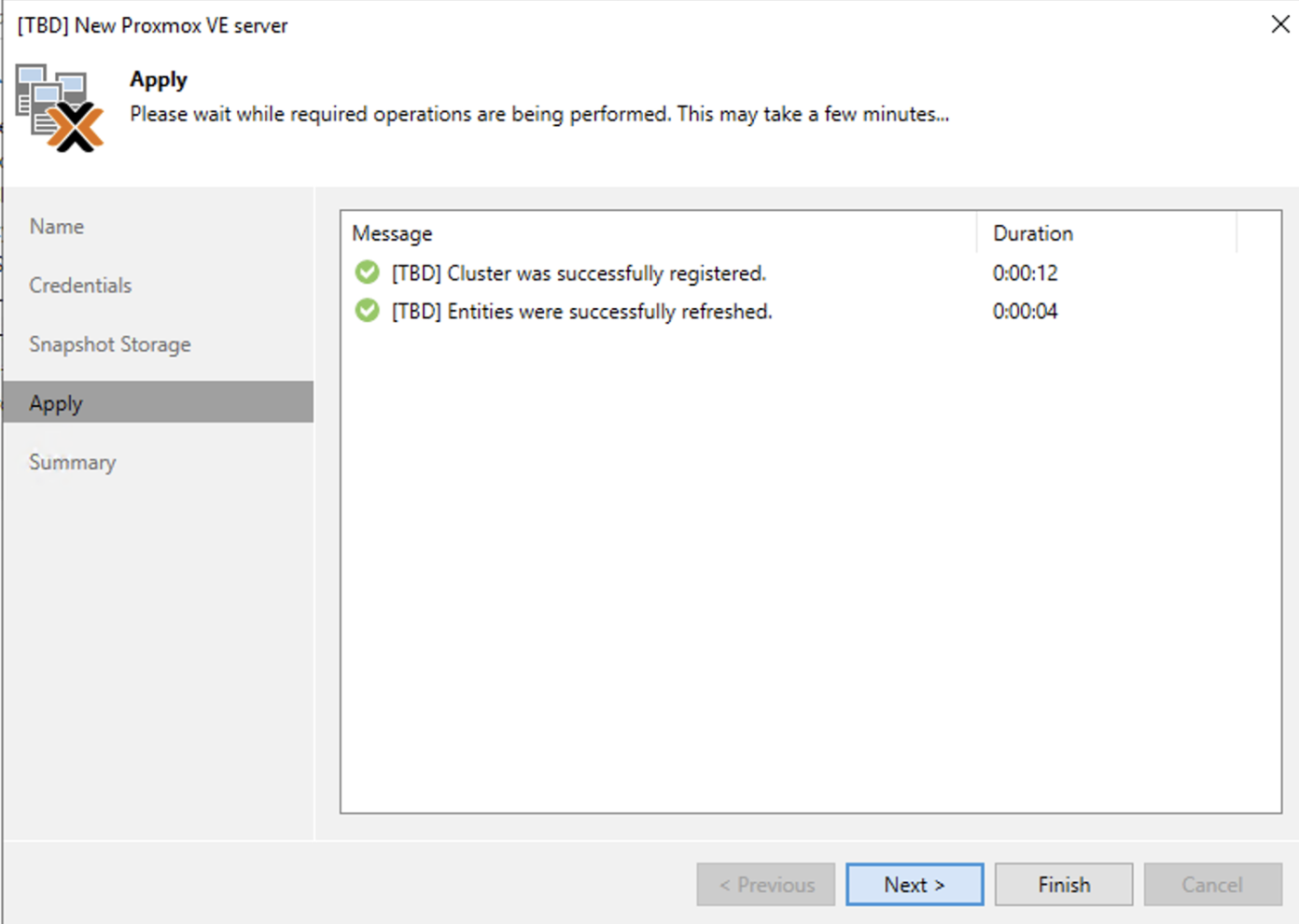 Immagine 8
Immagine 8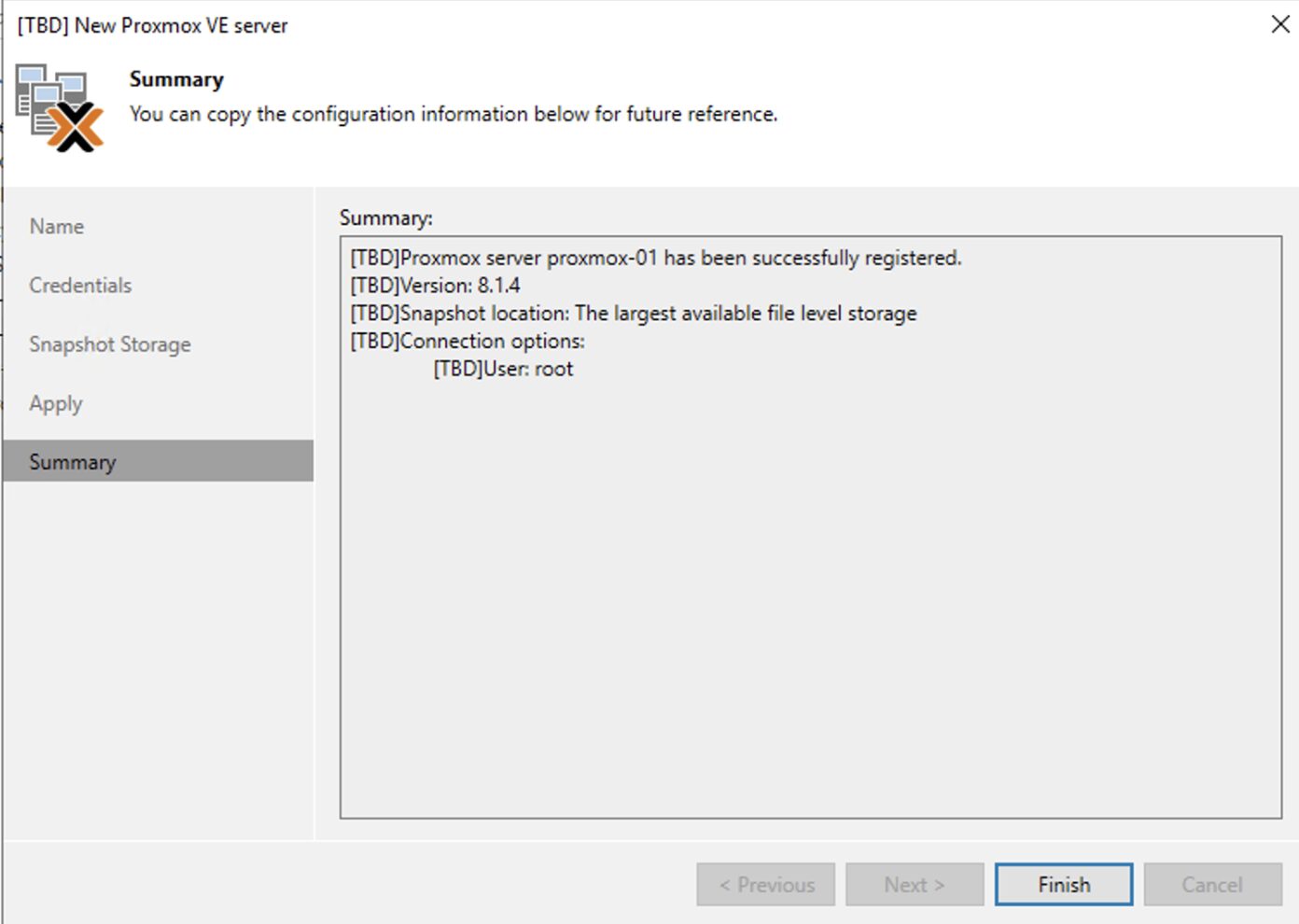 Immagine 9
Immagine 9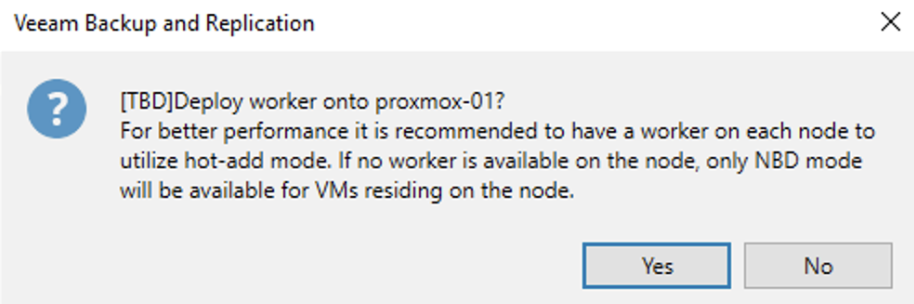 Immagine 10
Immagine 10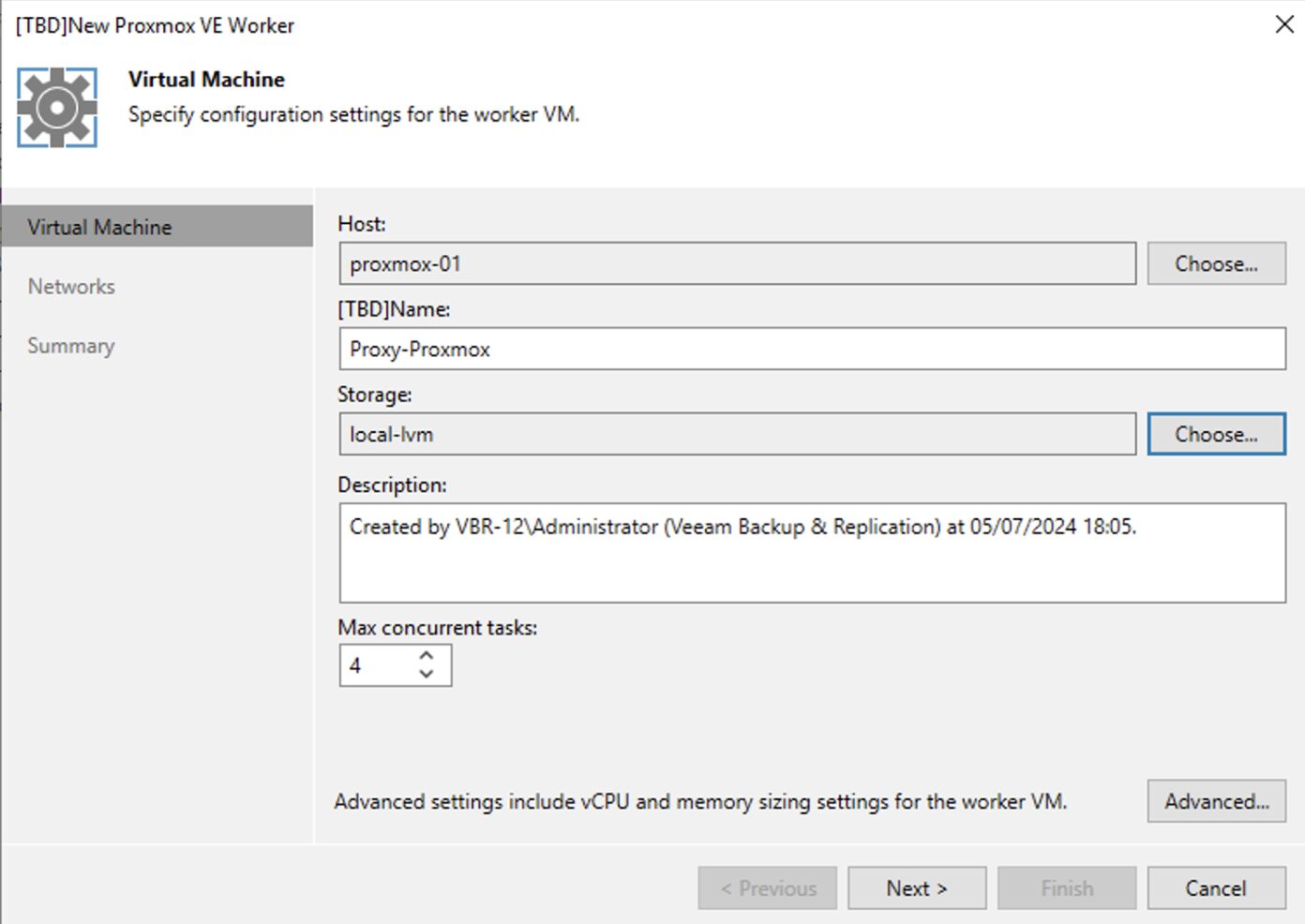 Immagine 11
Immagine 11 Immagine 12
Immagine 12 Immagine 13
Immagine 13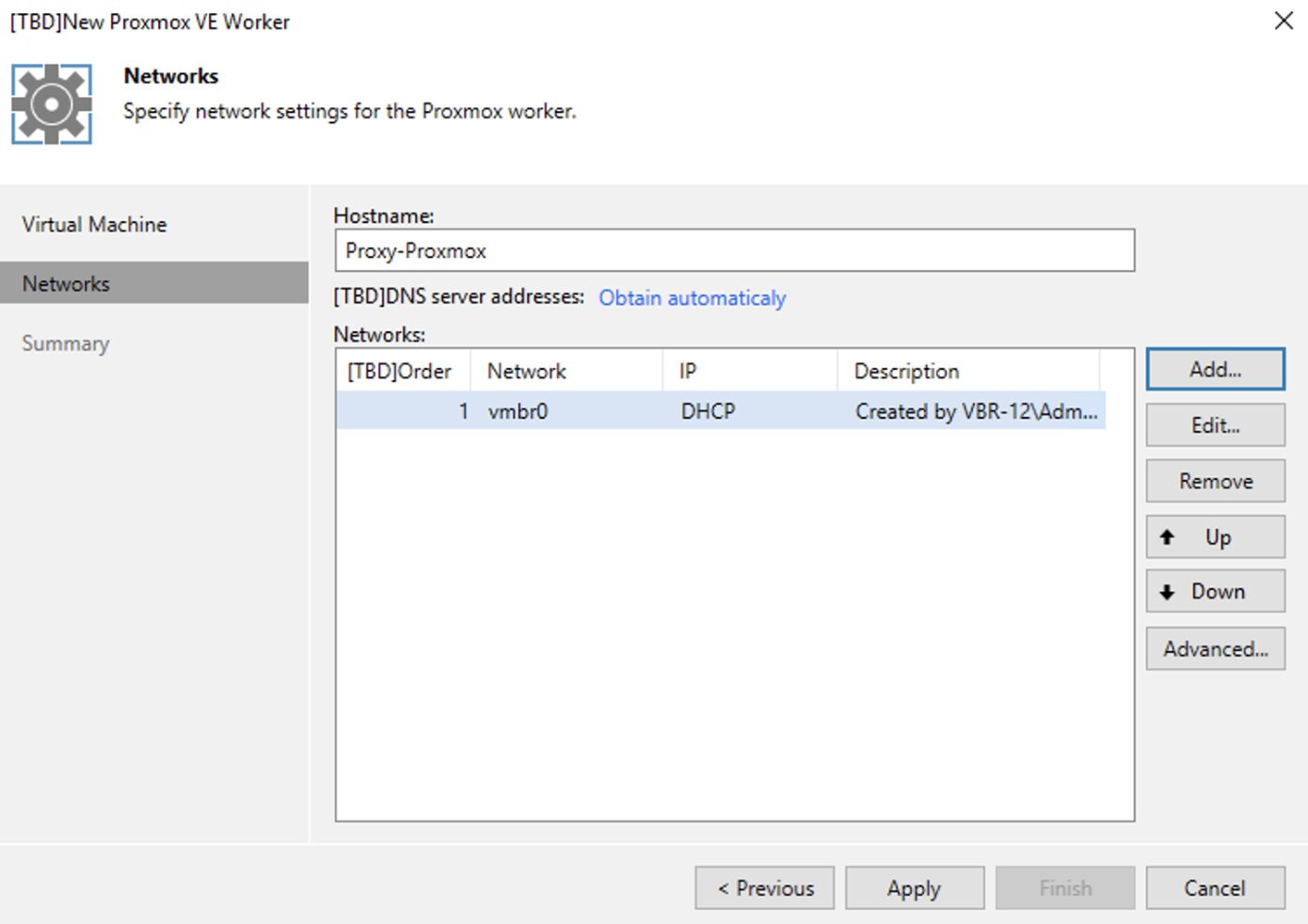 Immagine 14
Immagine 14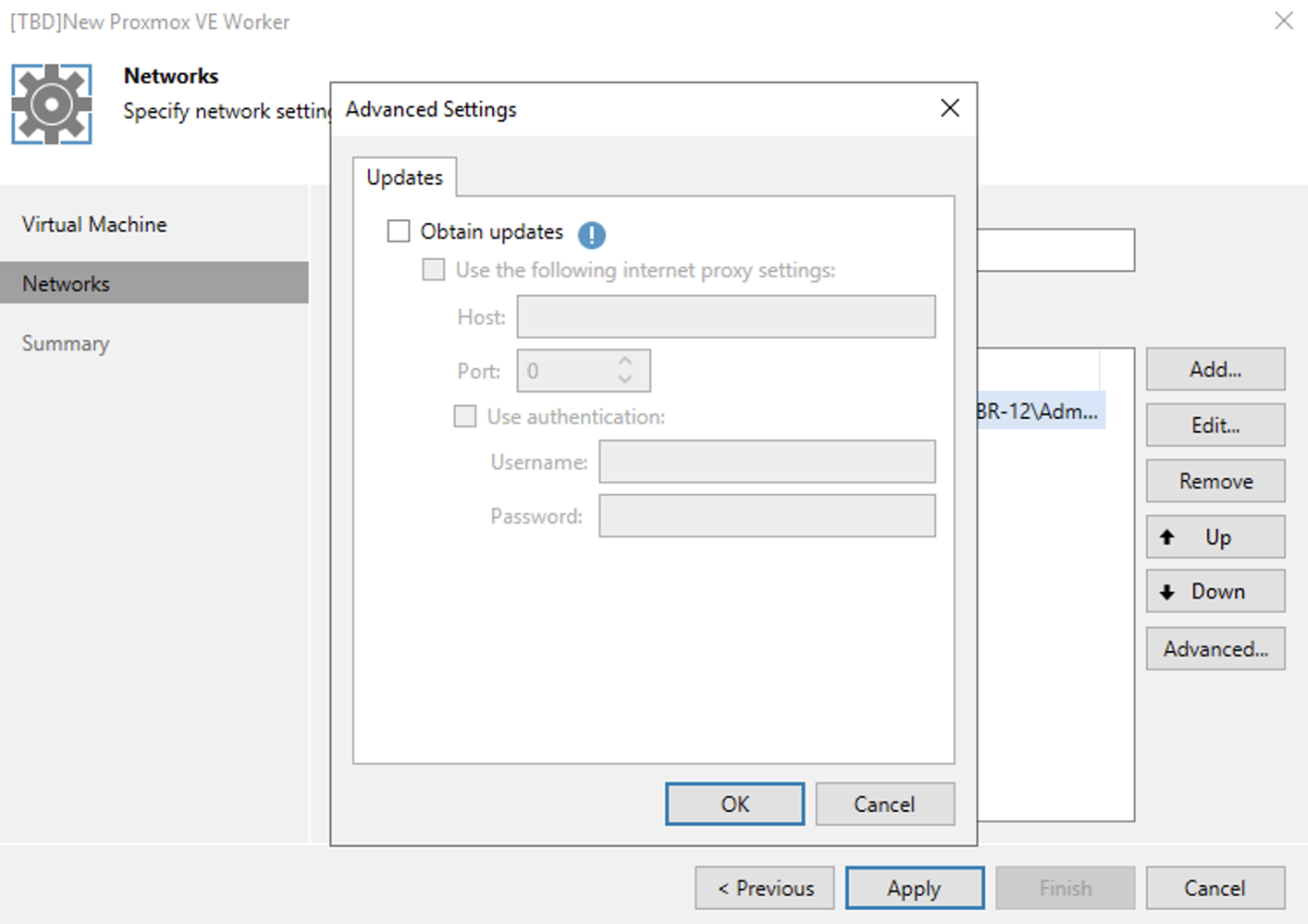 Immagine 15
Immagine 15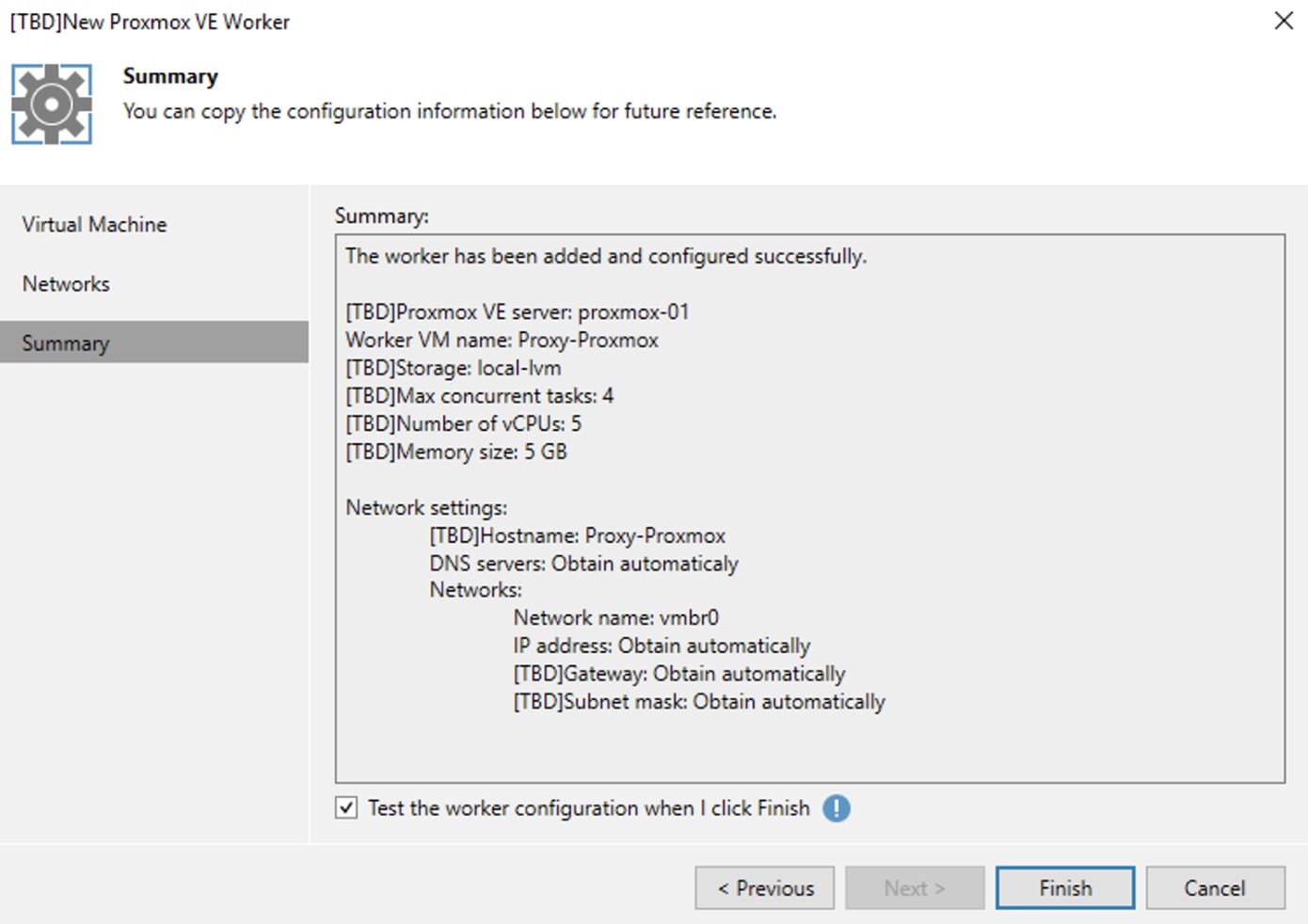 Immagine 16
Immagine 16 Immagine 1
Immagine 1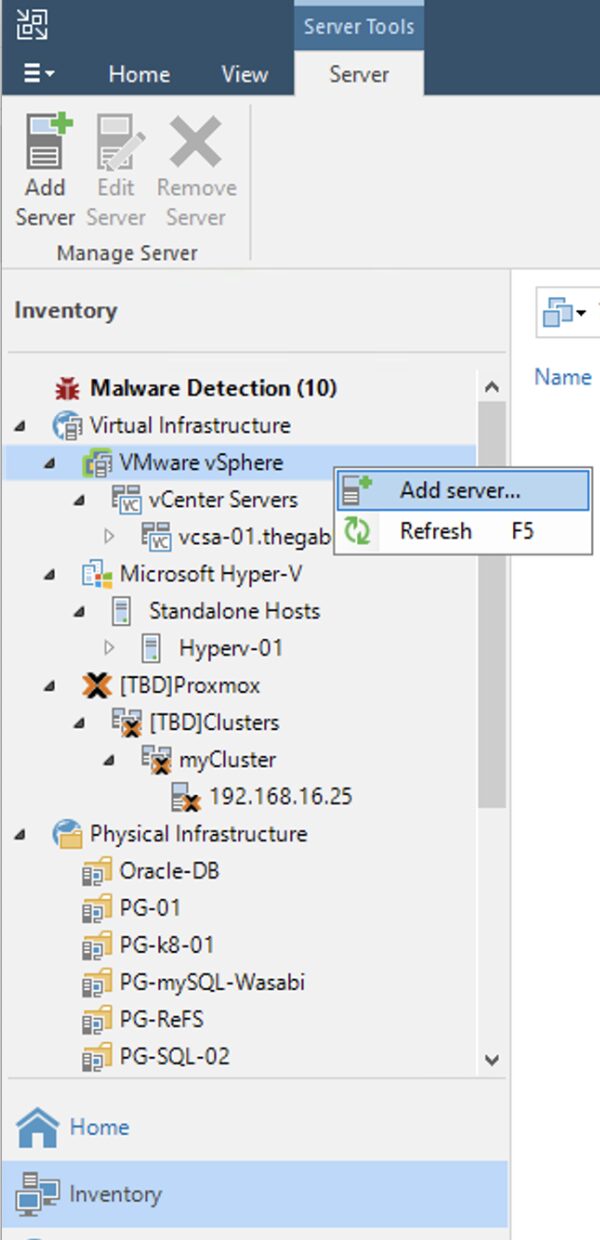 Immagine 2
Immagine 2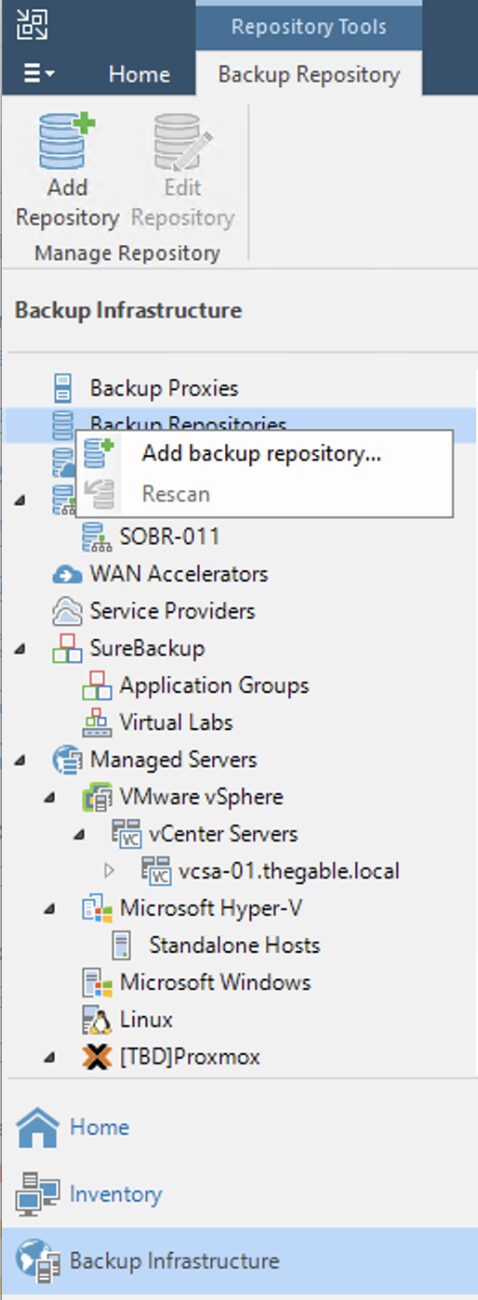 Immagine 3
Immagine 3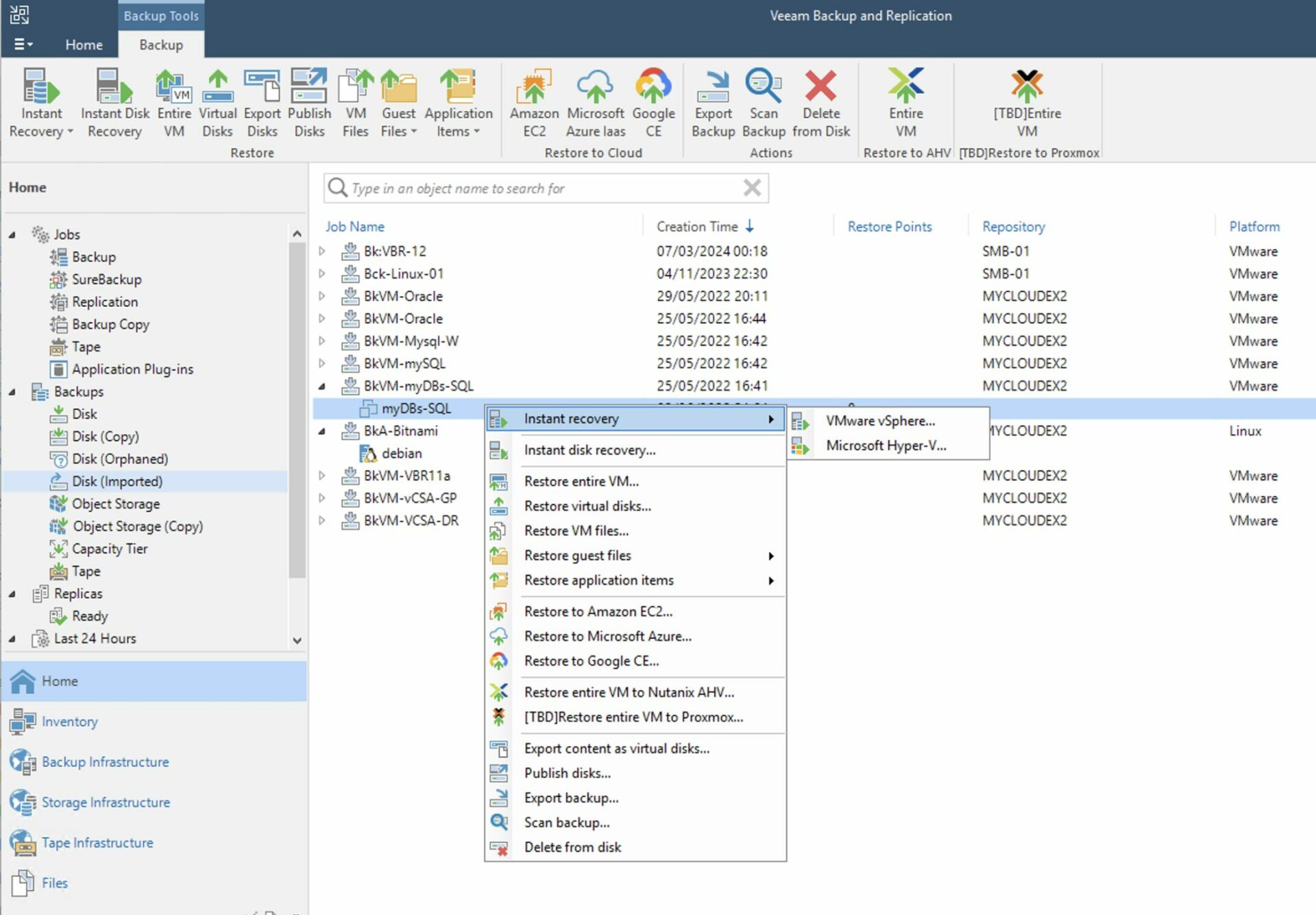 Immagine 4
Immagine 4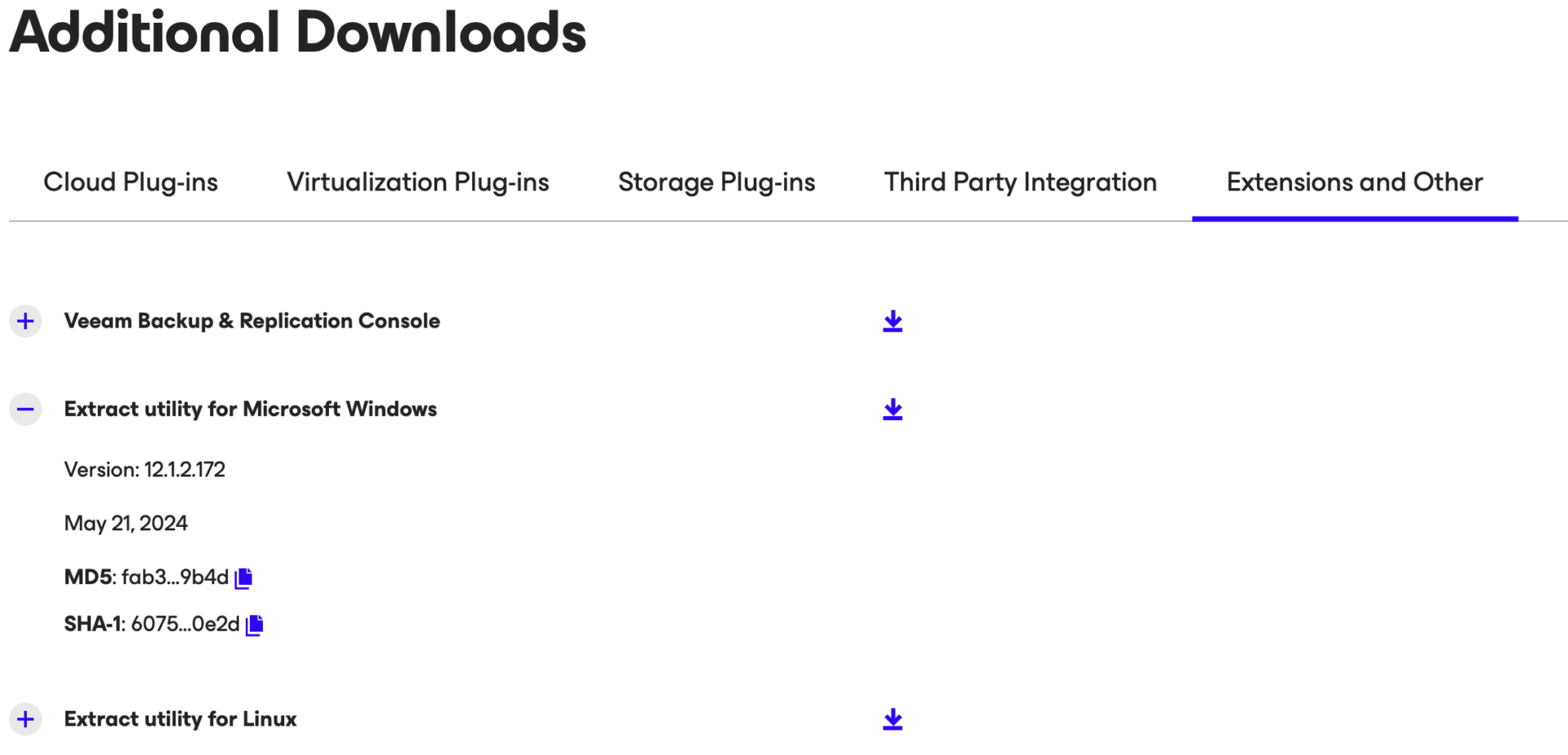 Immagine 5
Immagine 5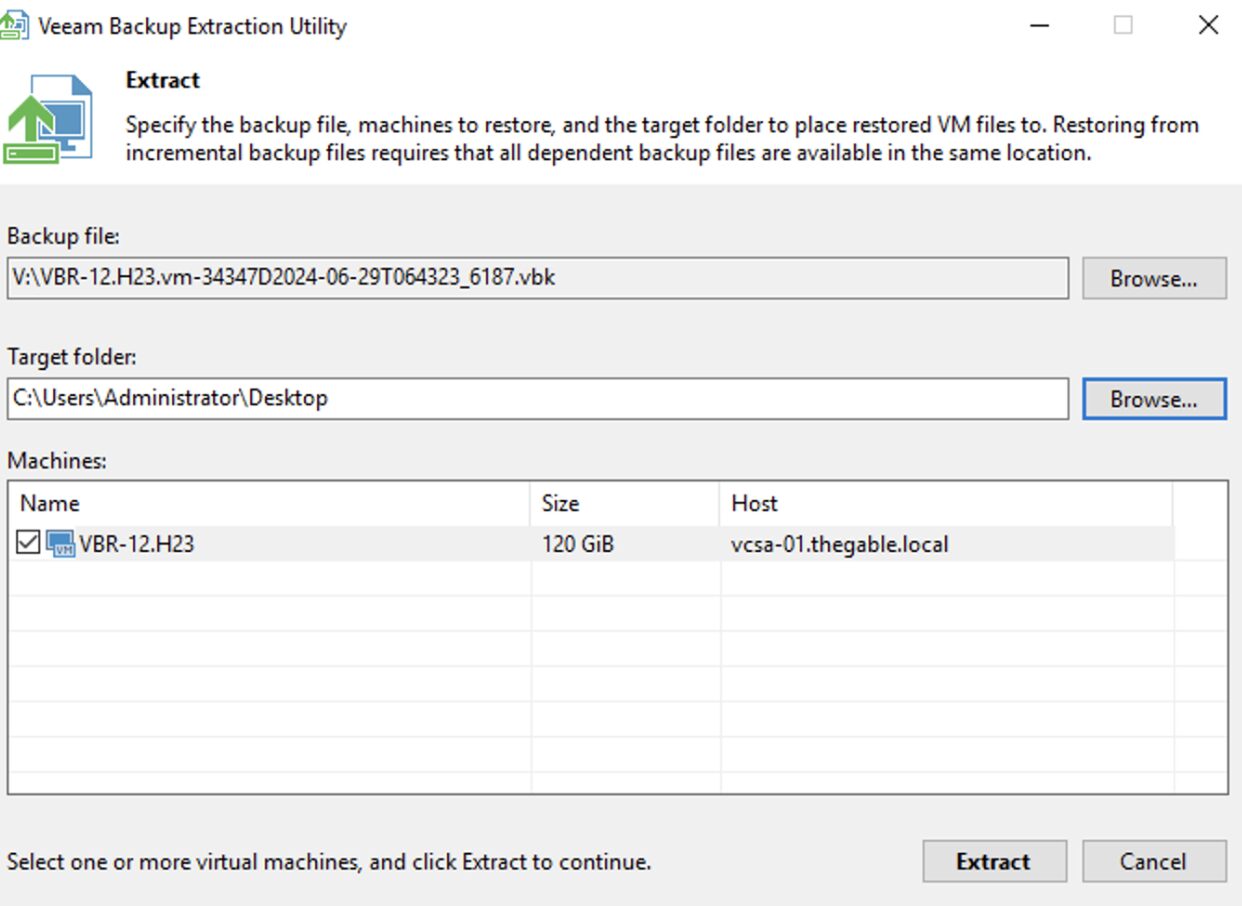 (Immagine 6)
(Immagine 6) Immagine 7
Immagine 7 Immagine 8
Immagine 8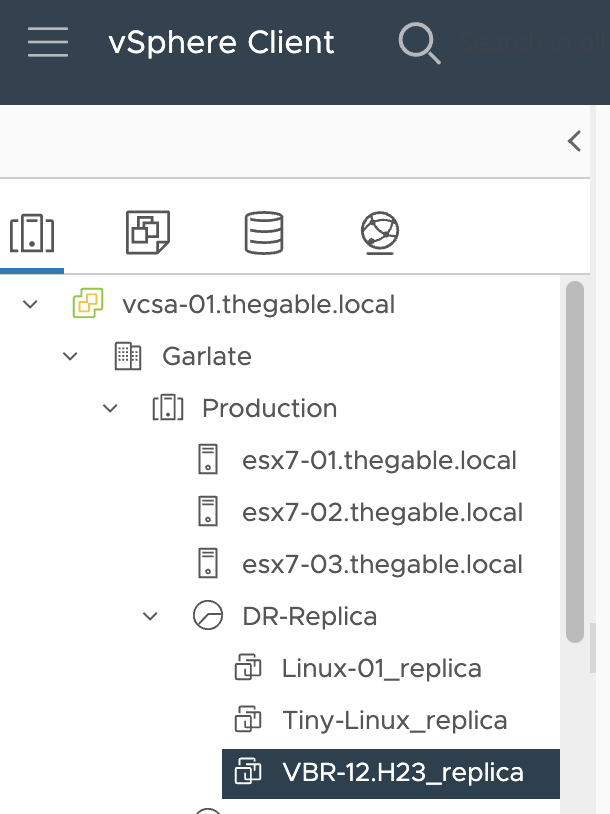 Immagine 9
Immagine 9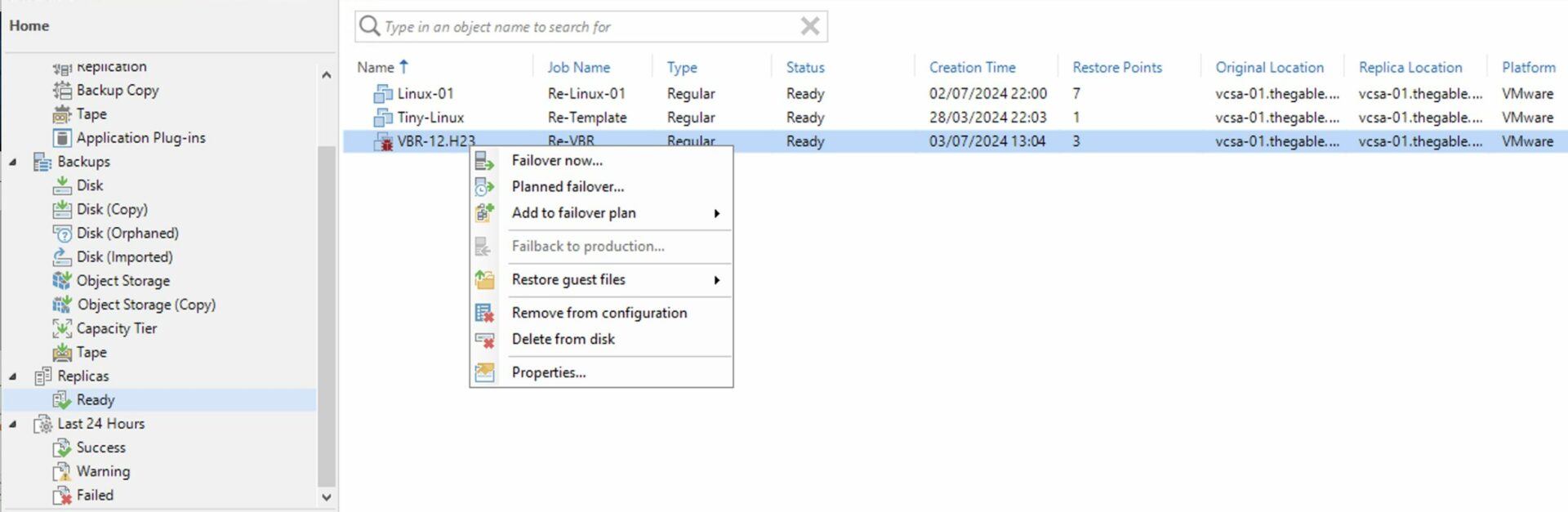 Immagine 10
Immagine 10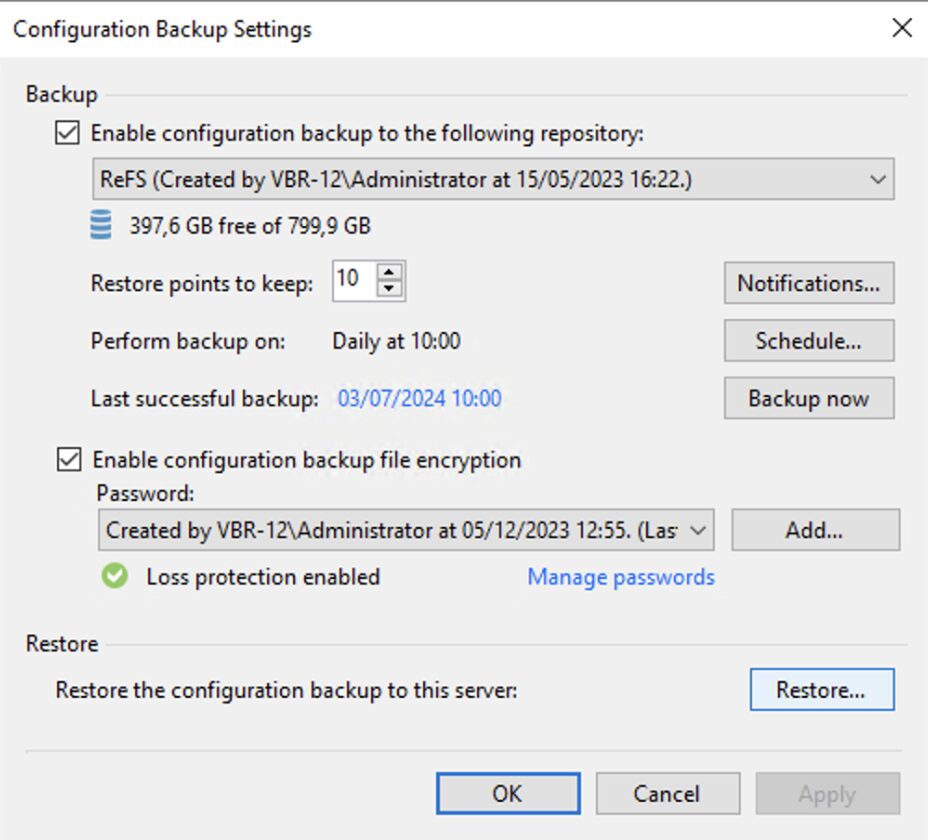 Immagine 11
Immagine 11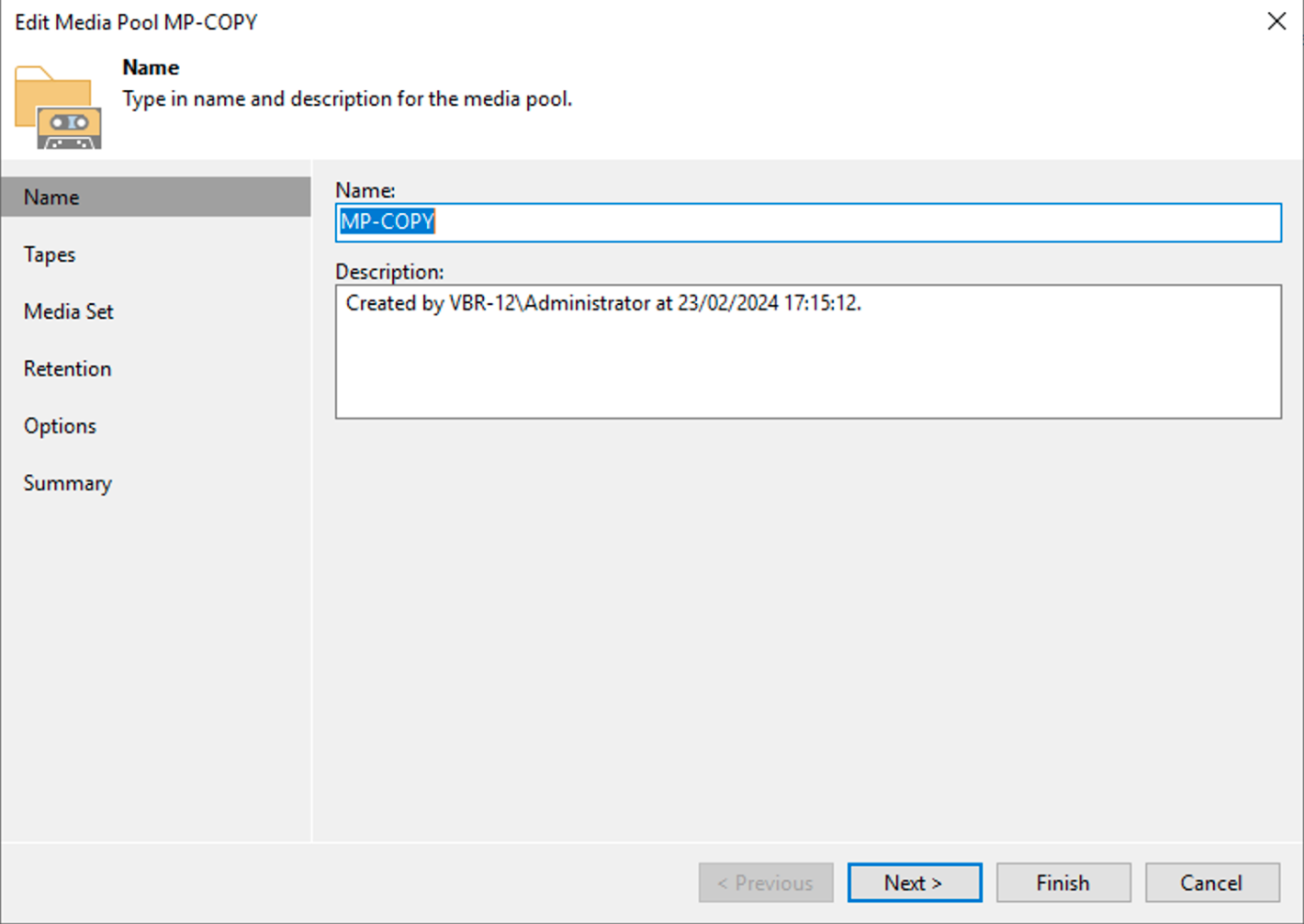 Immagine 1
Immagine 1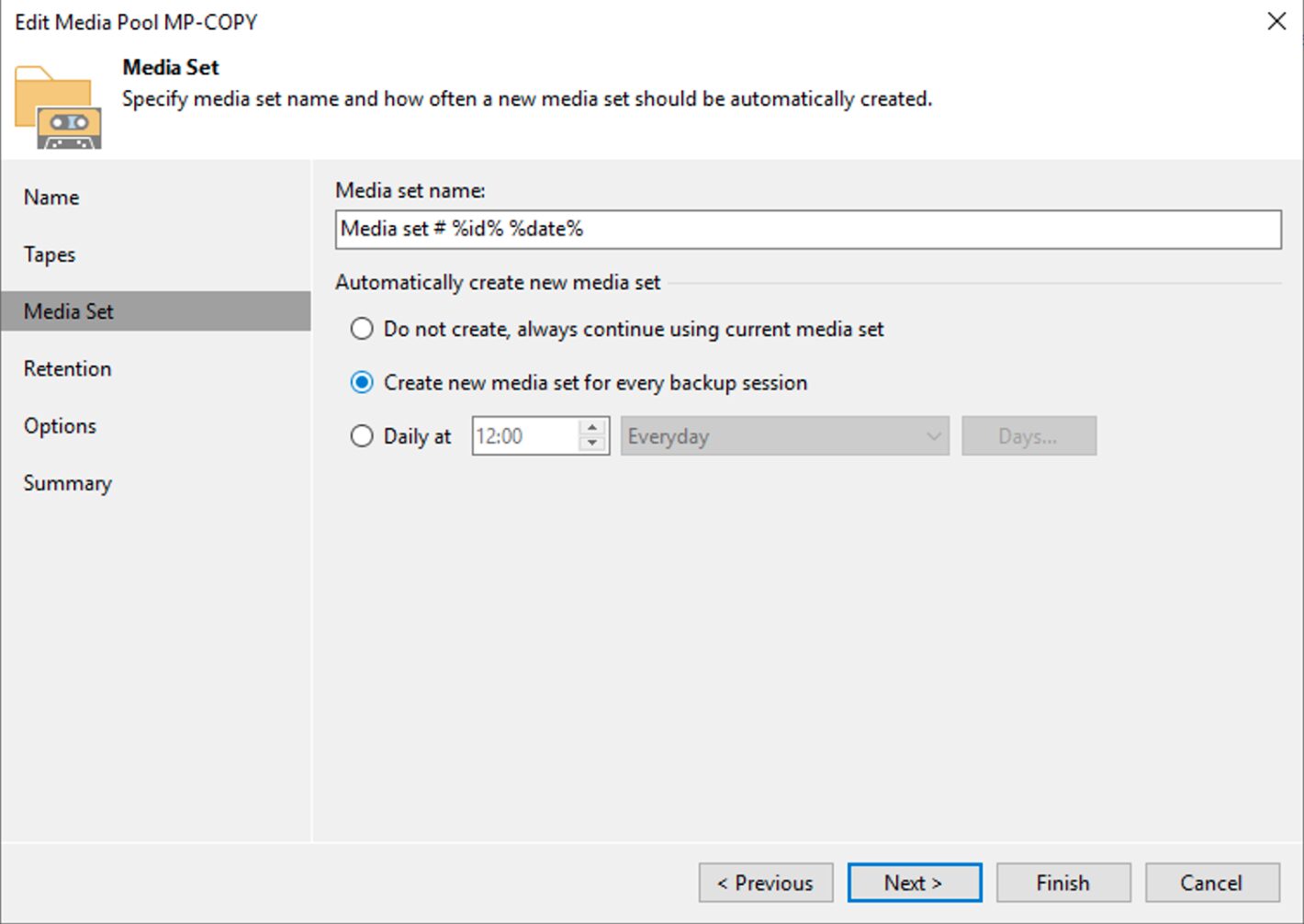 Immagine 2
Immagine 2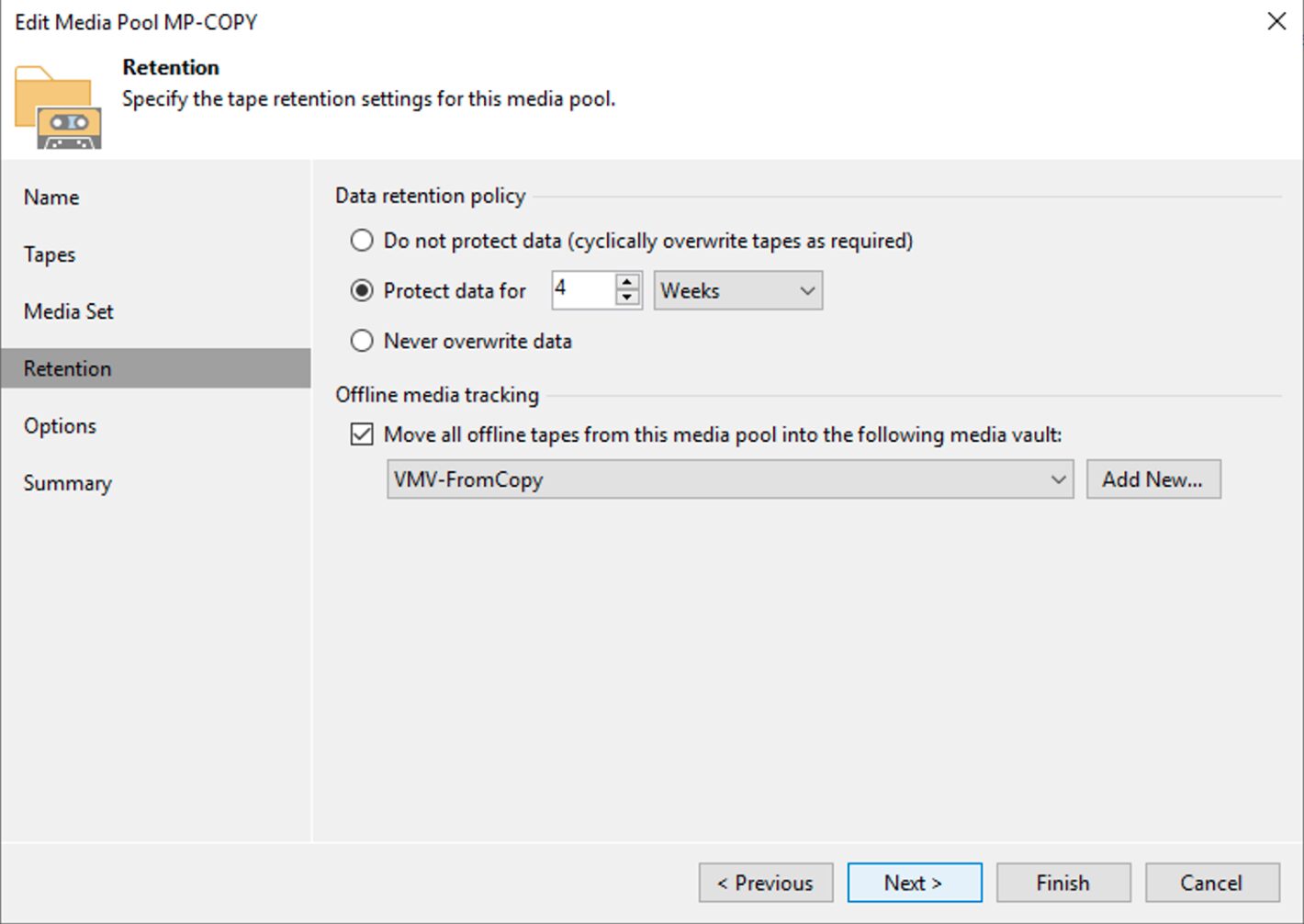 Immagine 3
Immagine 3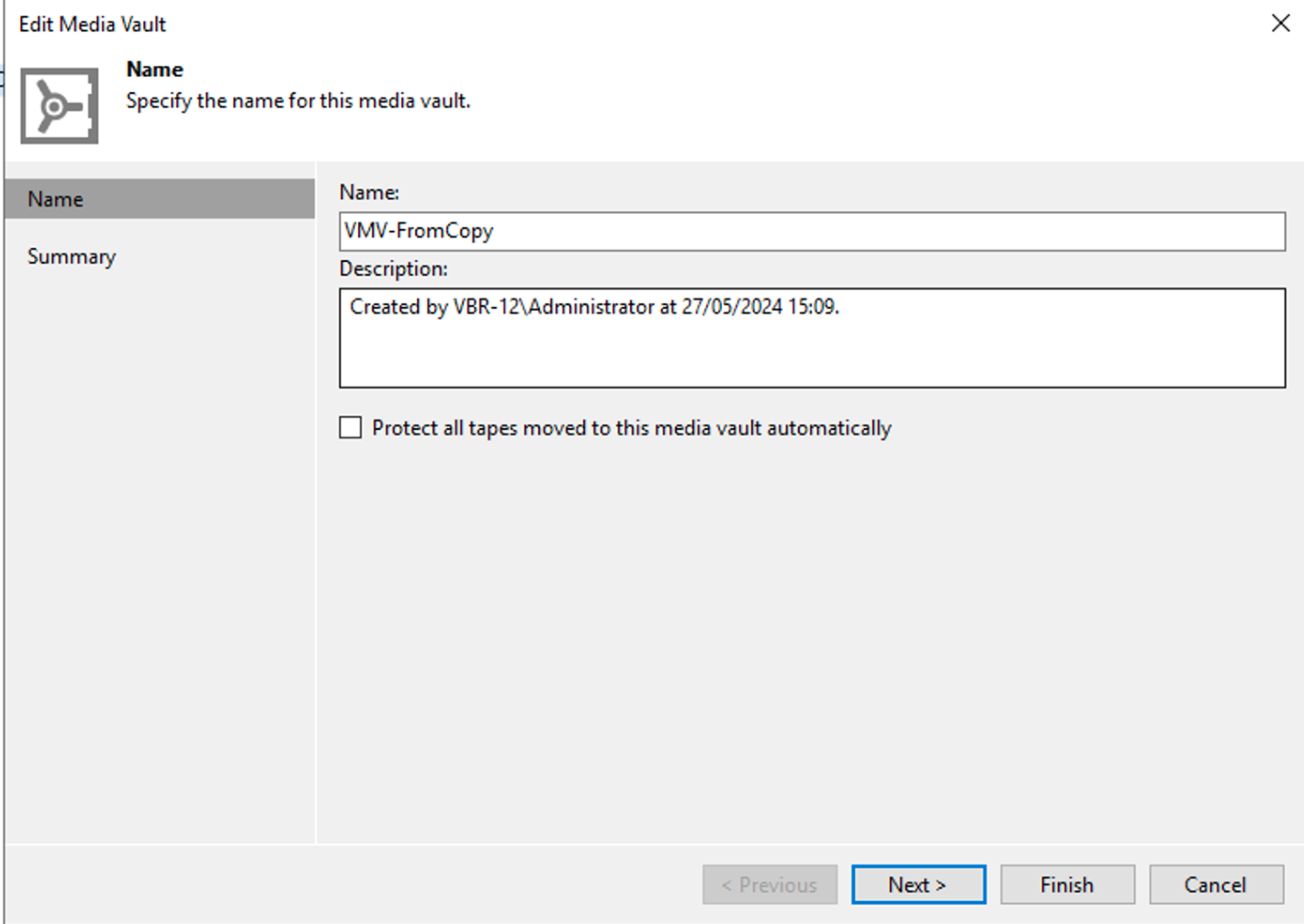 Immagine 4
Immagine 4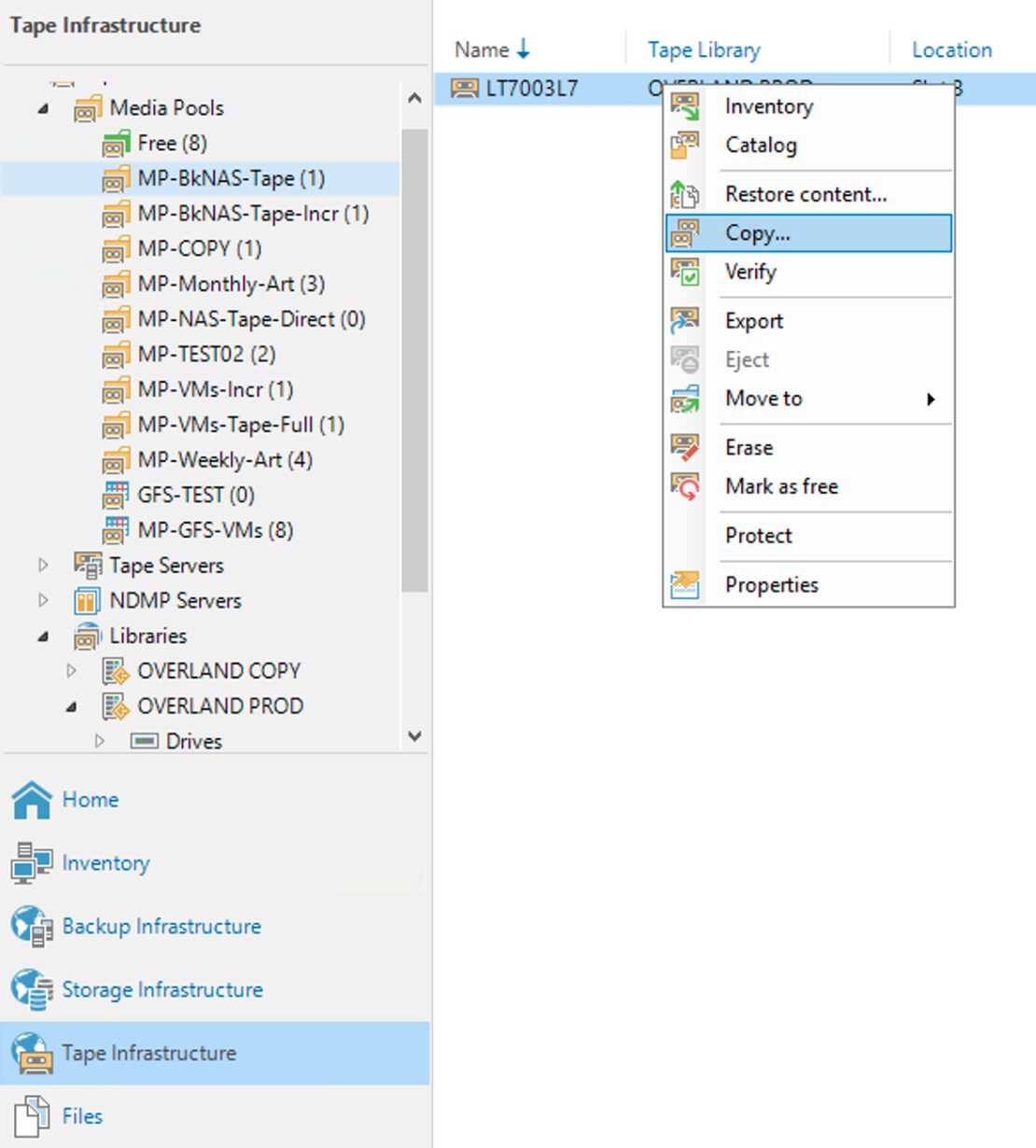 Immagine 5
Immagine 5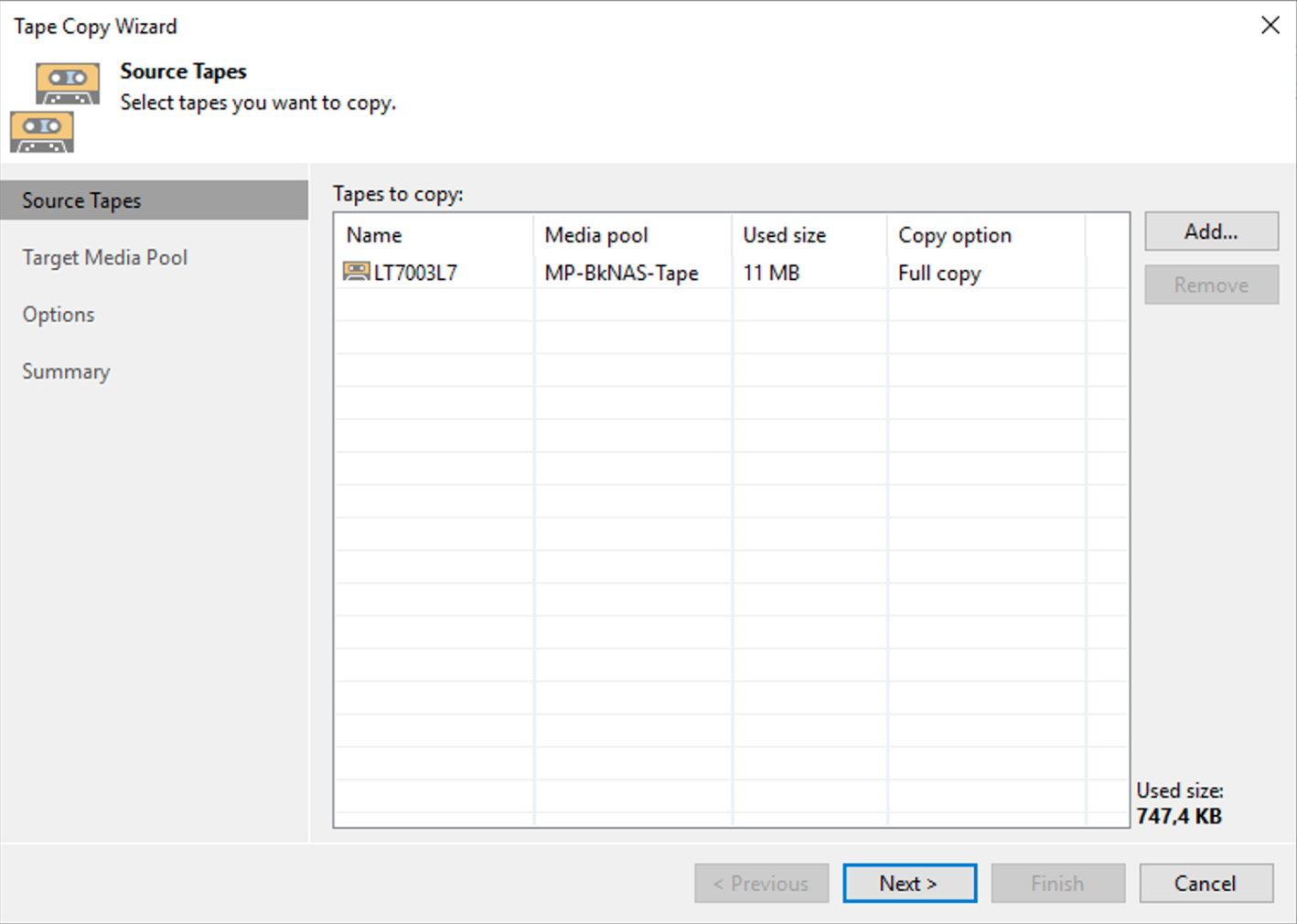 Immagine 6
Immagine 6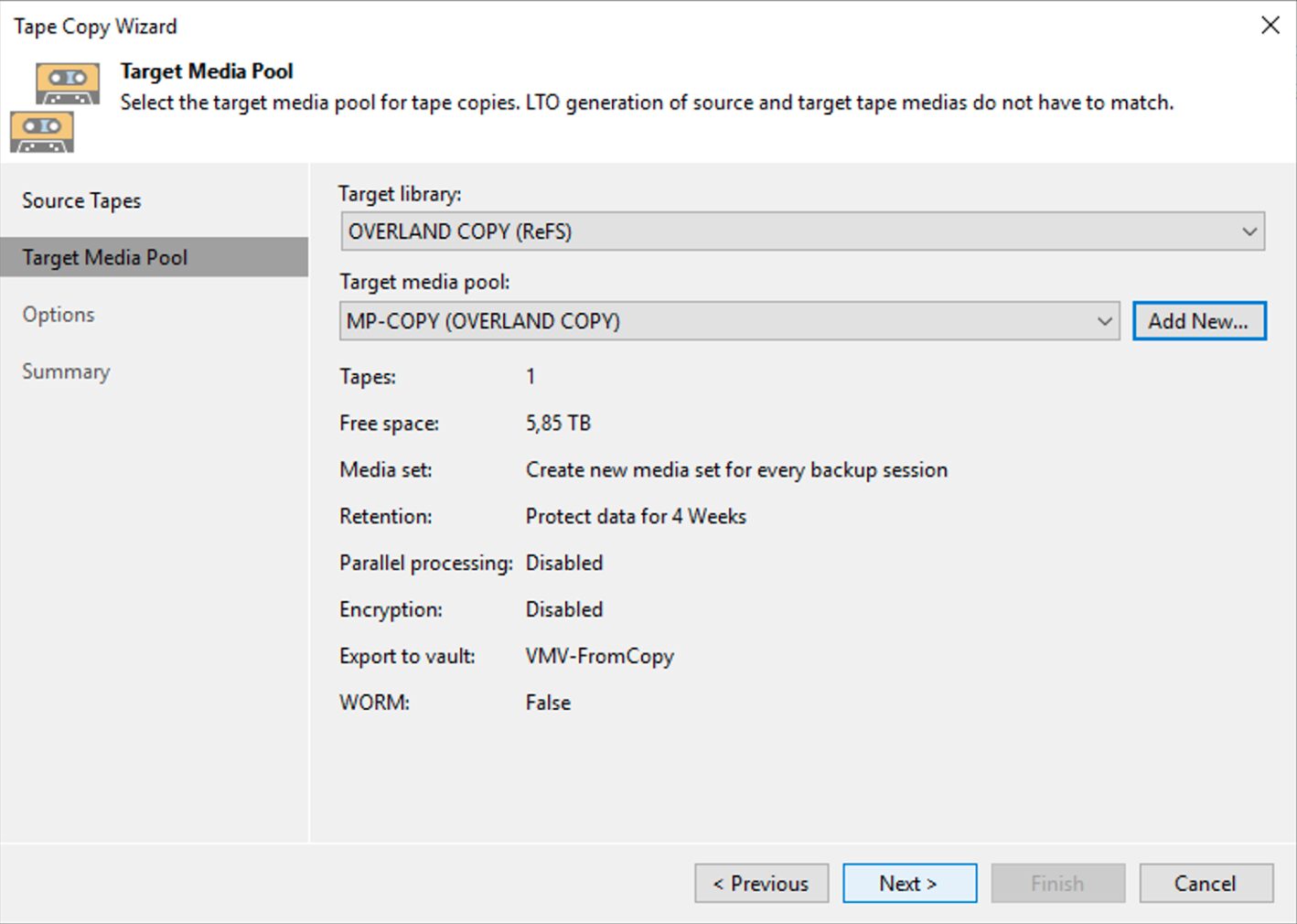 Immagine 7
Immagine 7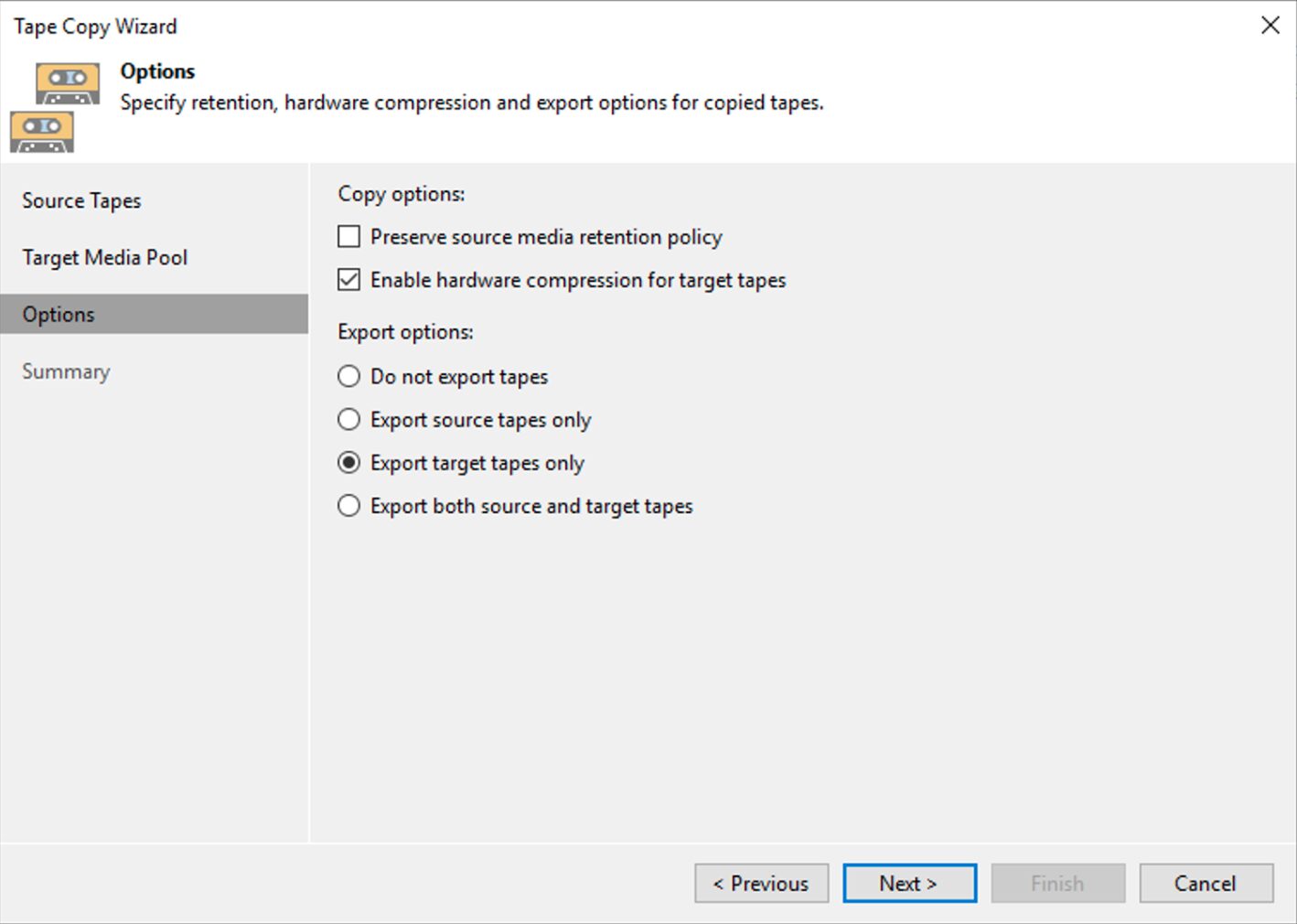 Immagine 8
Immagine 8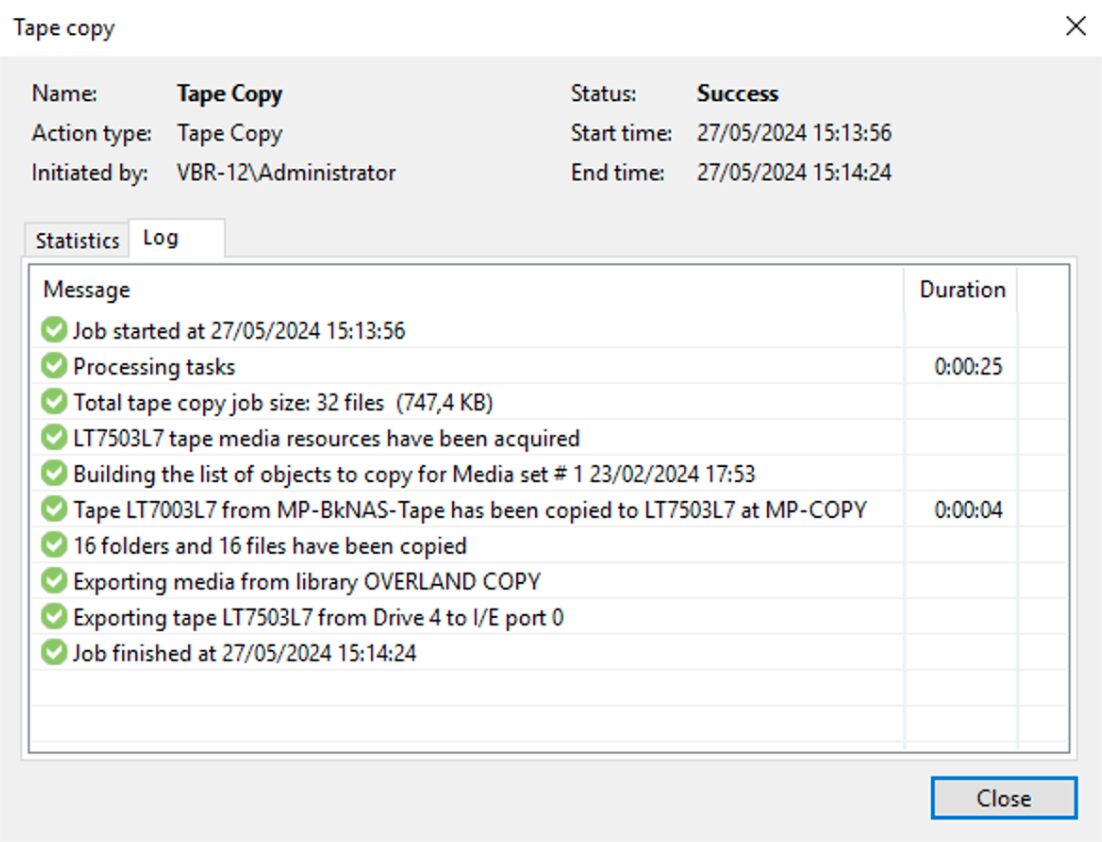 Immagine 9
Immagine 9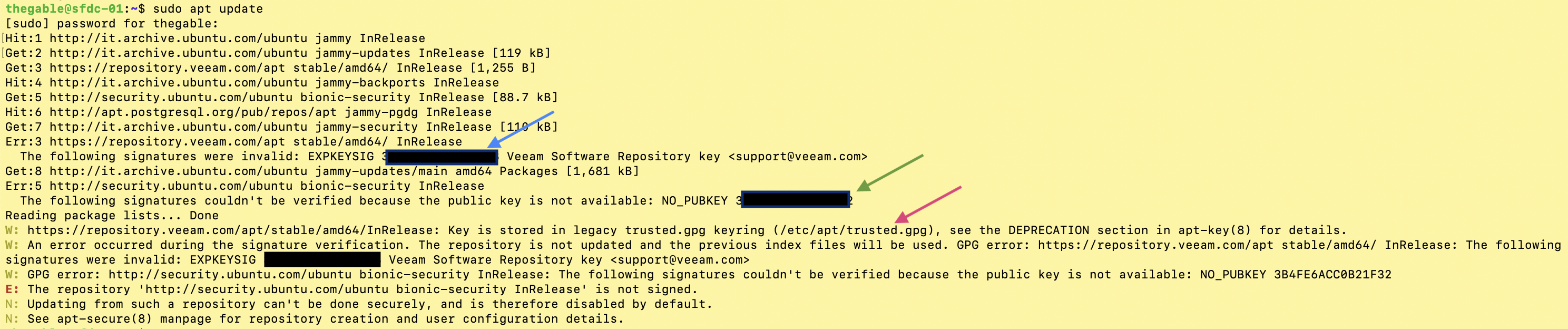 Immagine 1
Immagine 1 Immagine 2
Immagine 2 immagine 3
immagine 3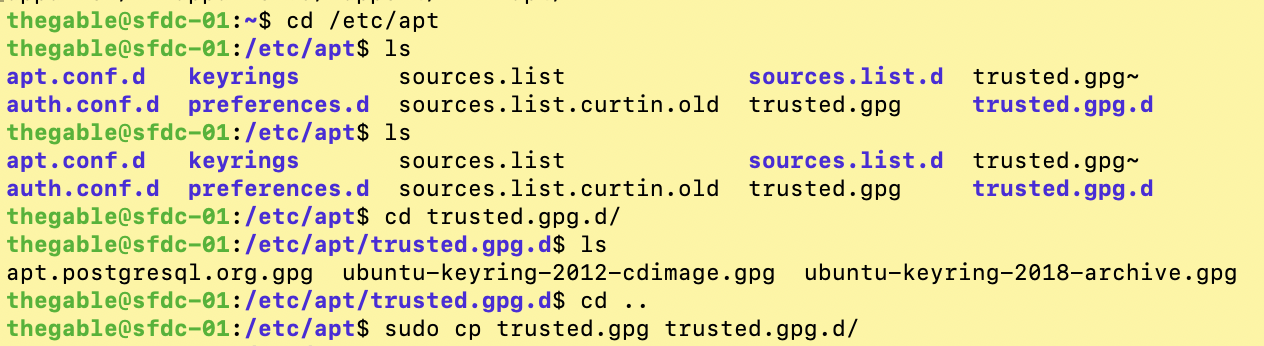 Immagine 4
Immagine 4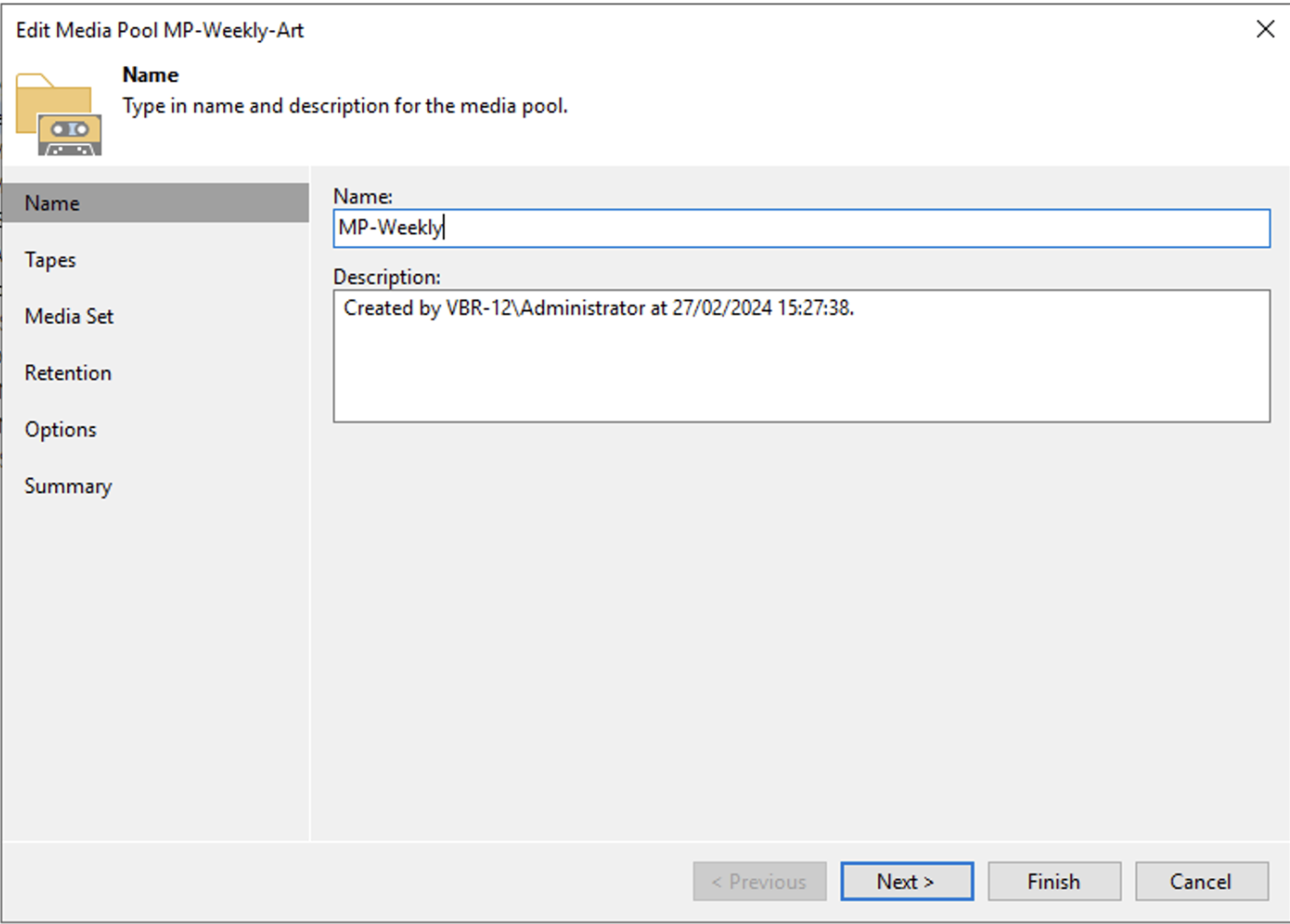 Immagine 1
Immagine 1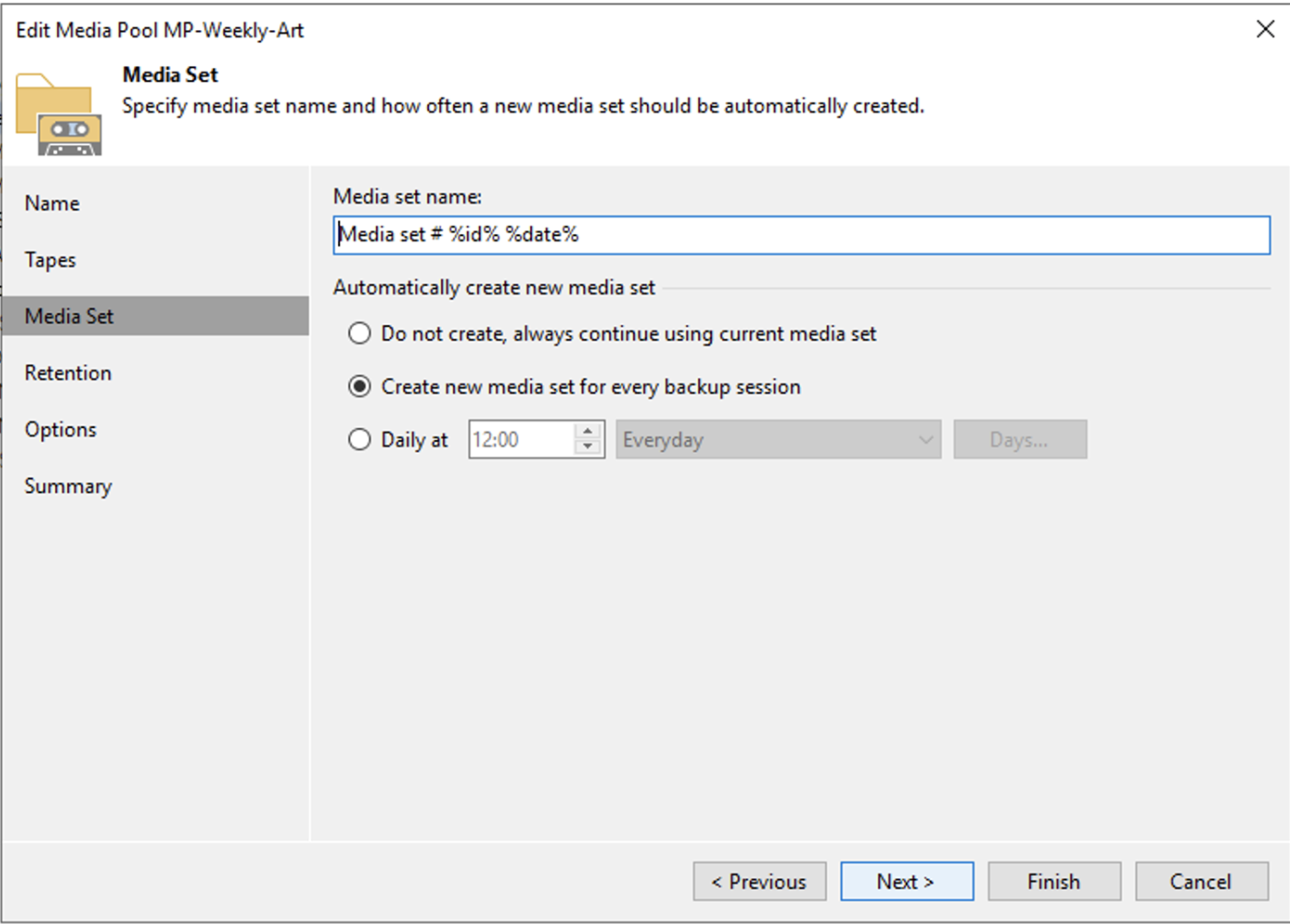 Immagine 2
Immagine 2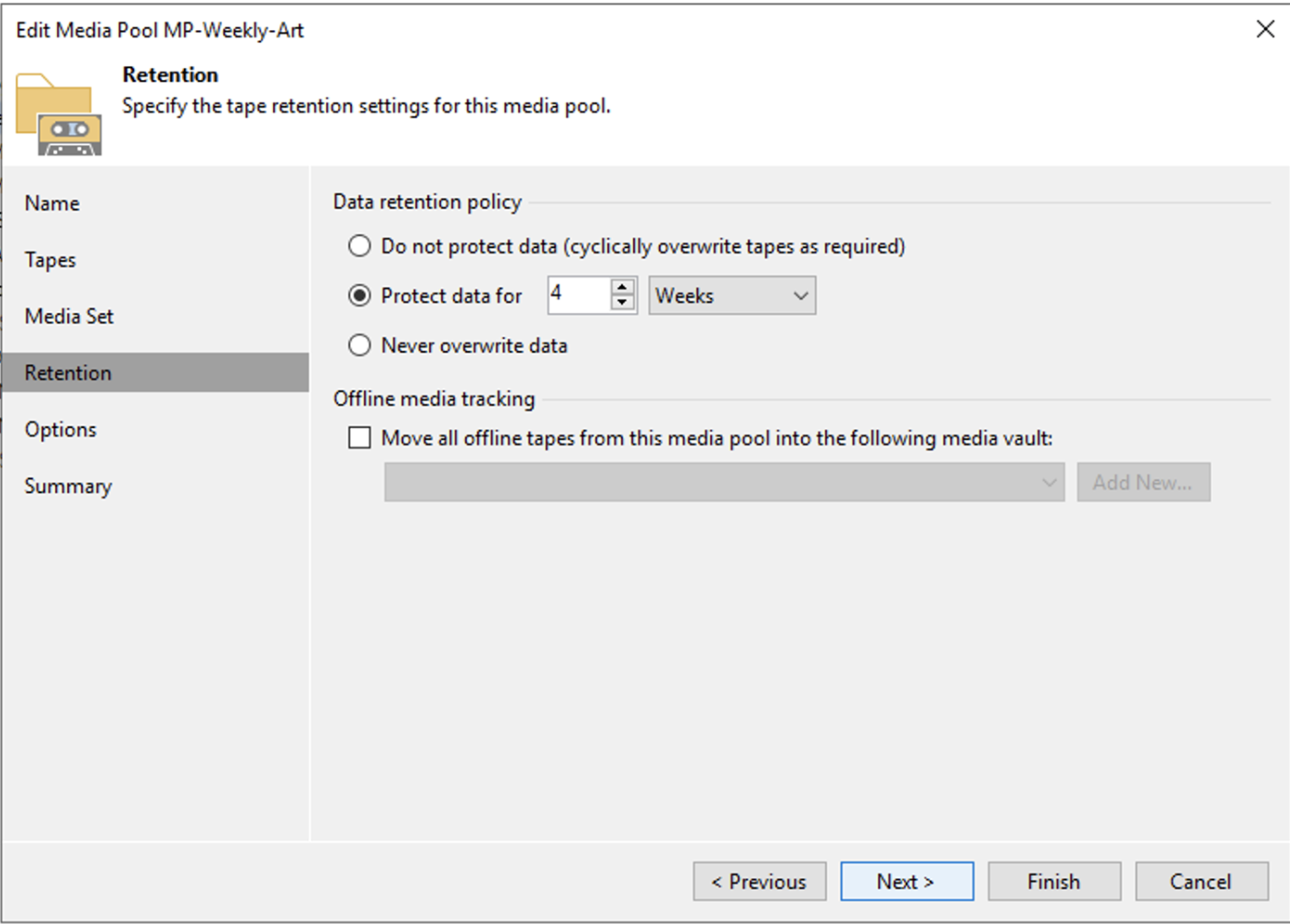 Immagine 3
Immagine 3 Immagine 4
Immagine 4 Immagine 5
Immagine 5 Immagine 6
Immagine 6 Immagine 7
Immagine 7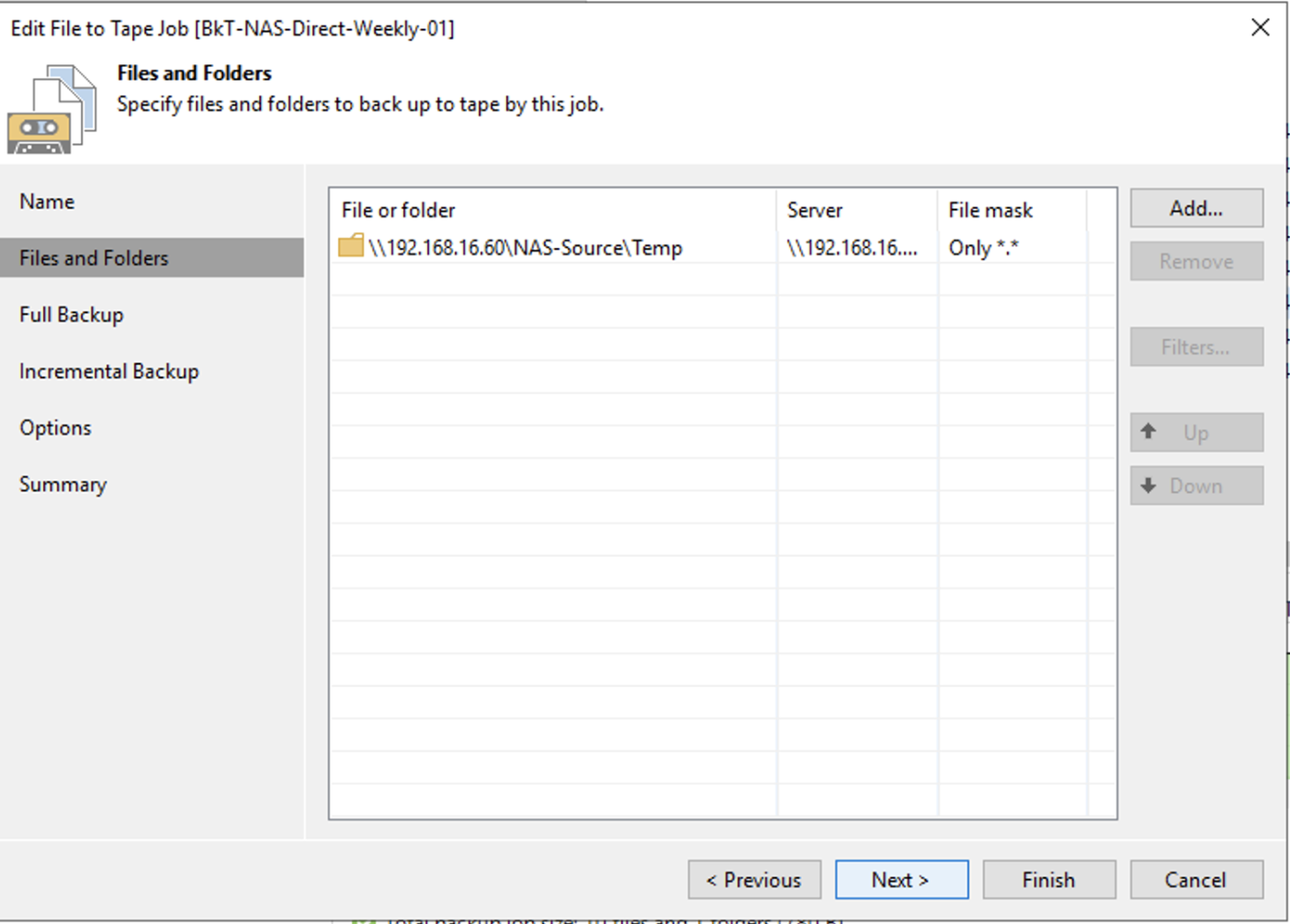 immagine 8
immagine 8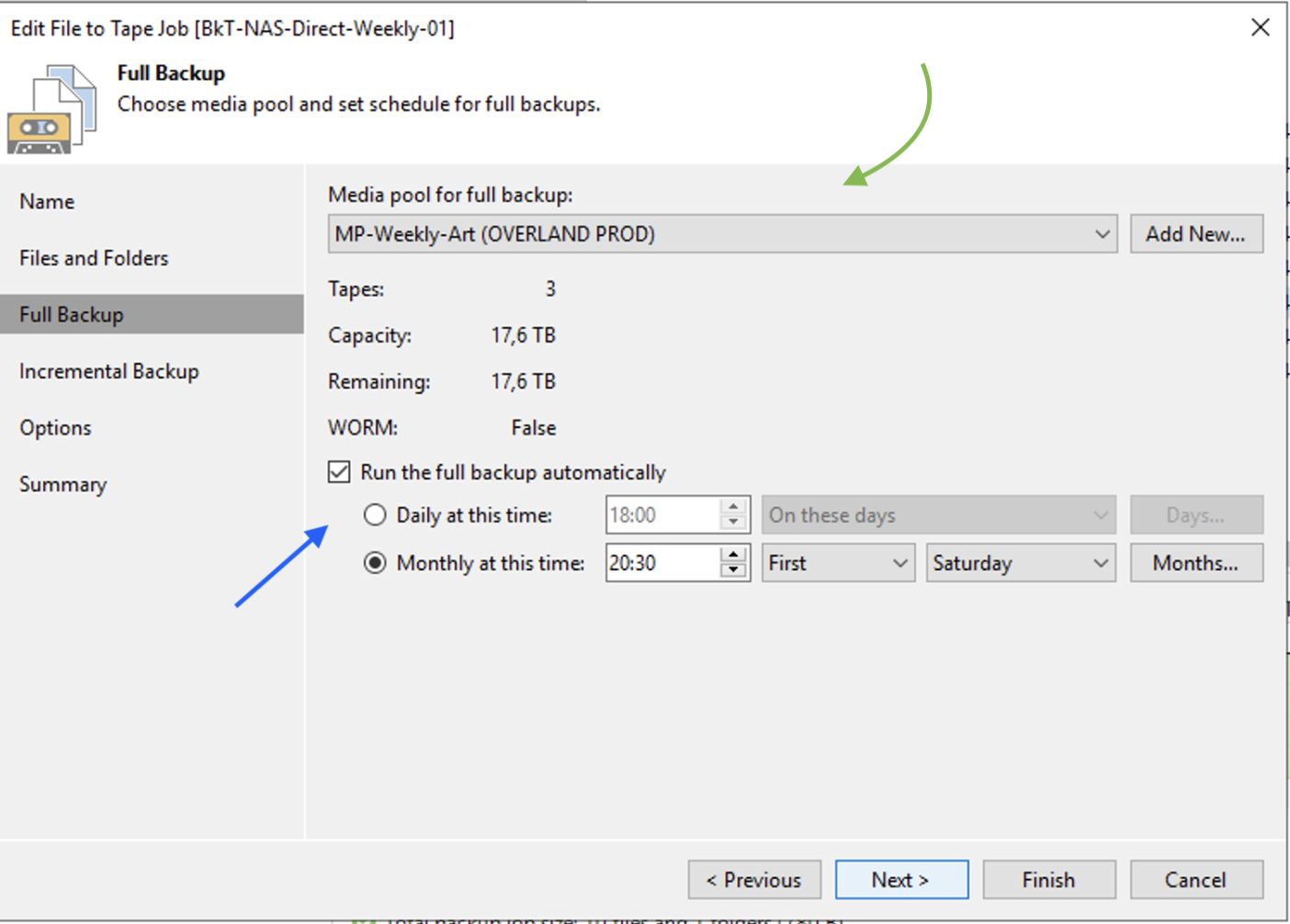 Immagine 9
Immagine 9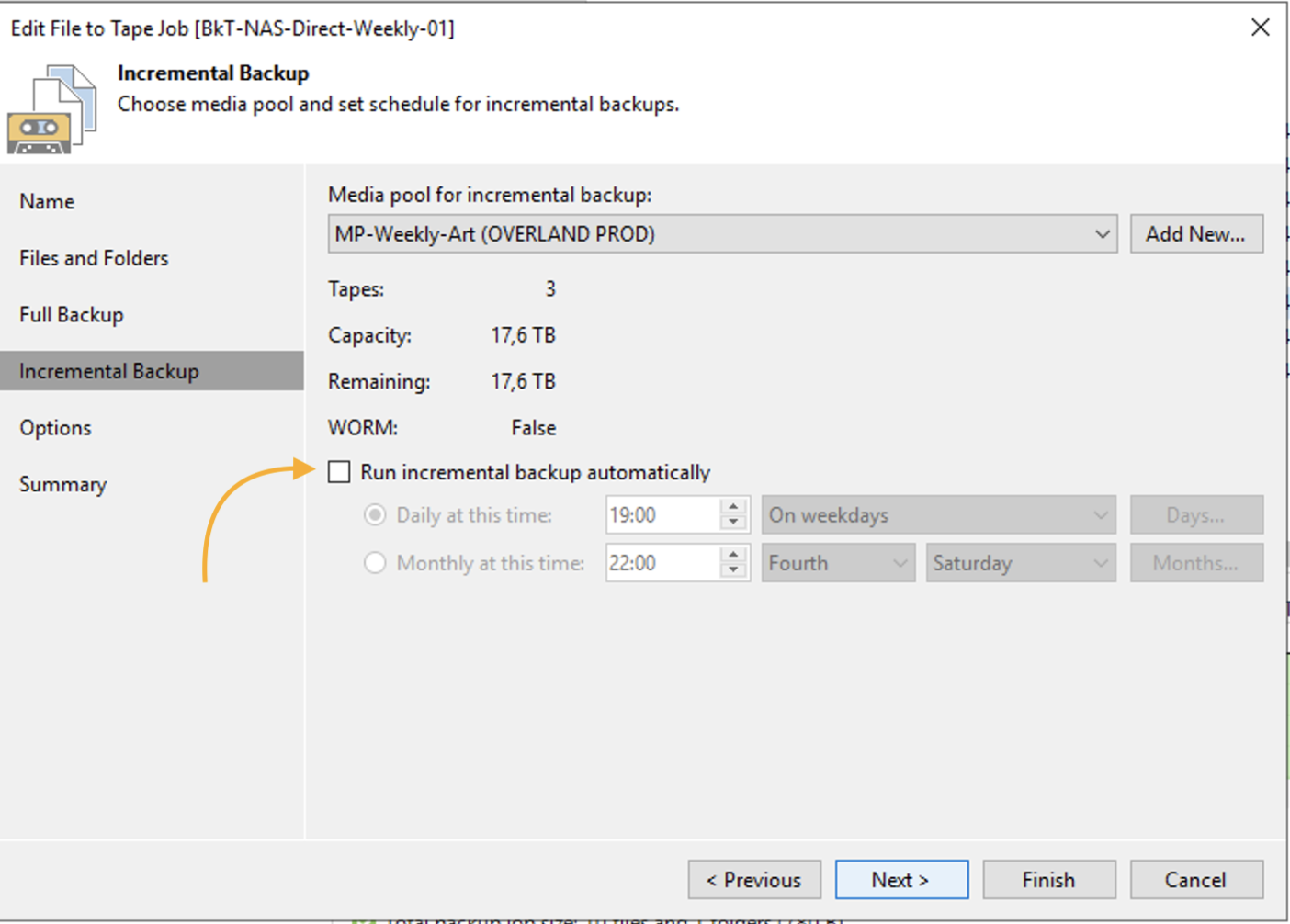 immagine 10
immagine 10 Immagine 11
Immagine 11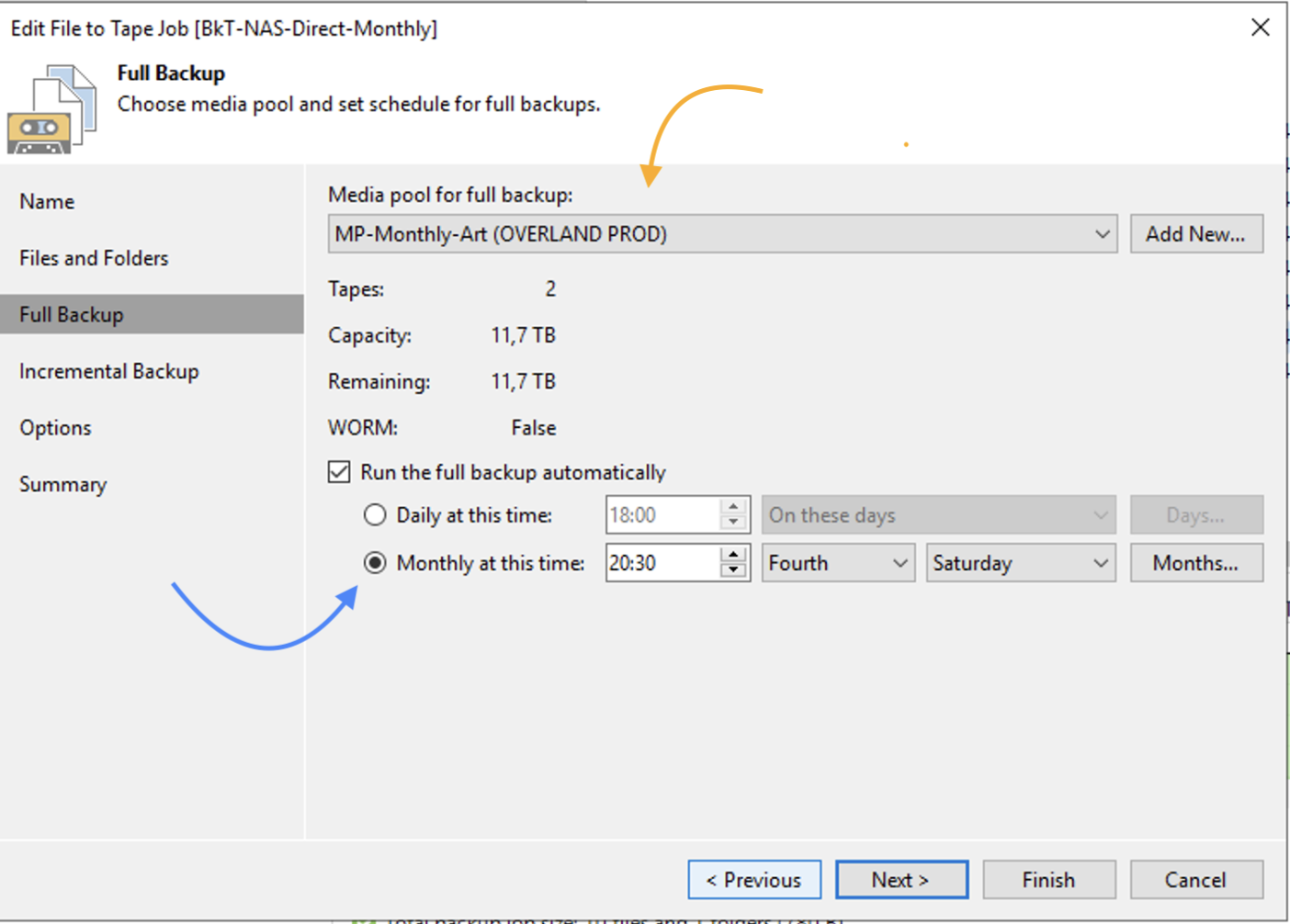 Immagine 12
Immagine 12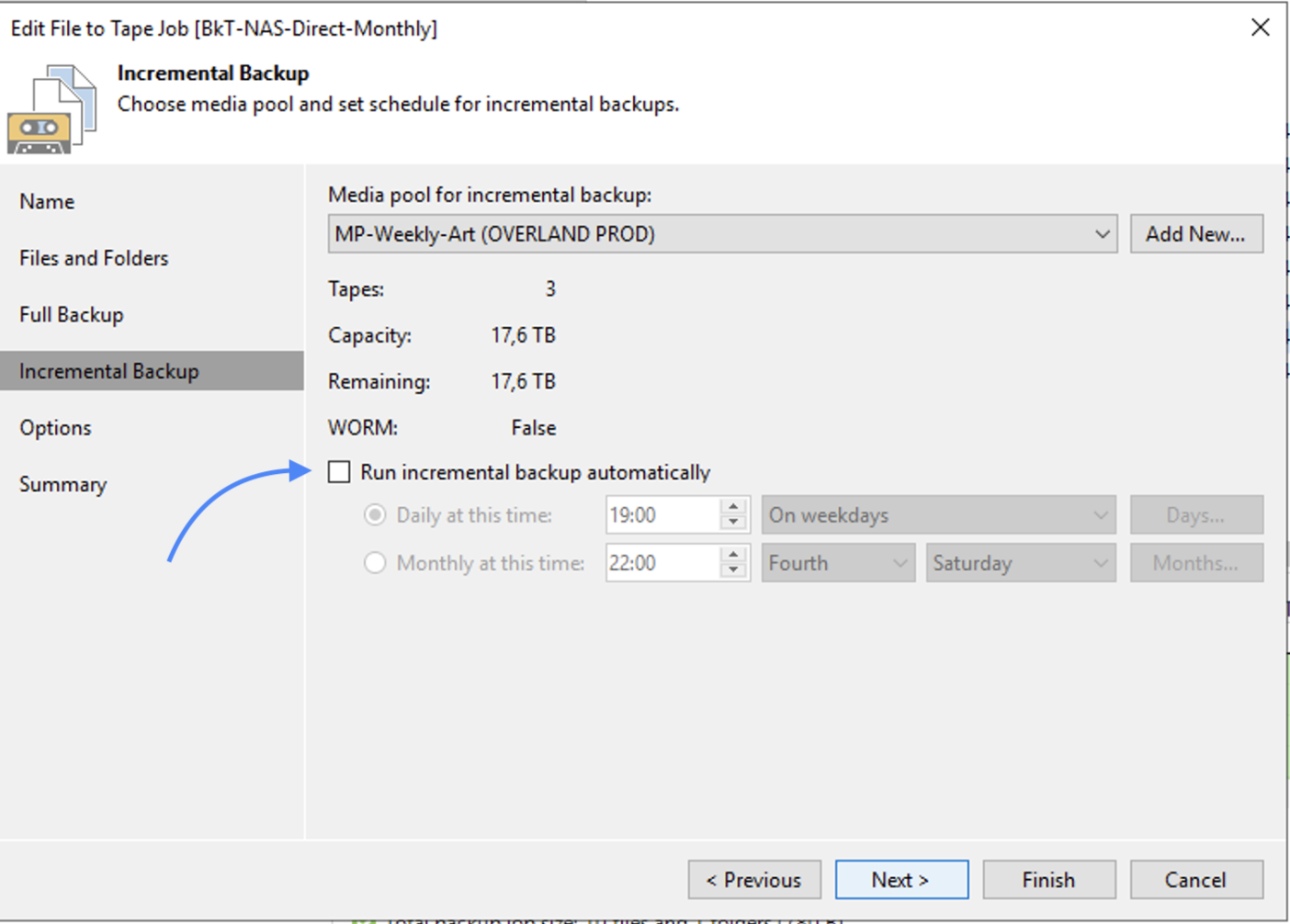 Immagine 13
Immagine 13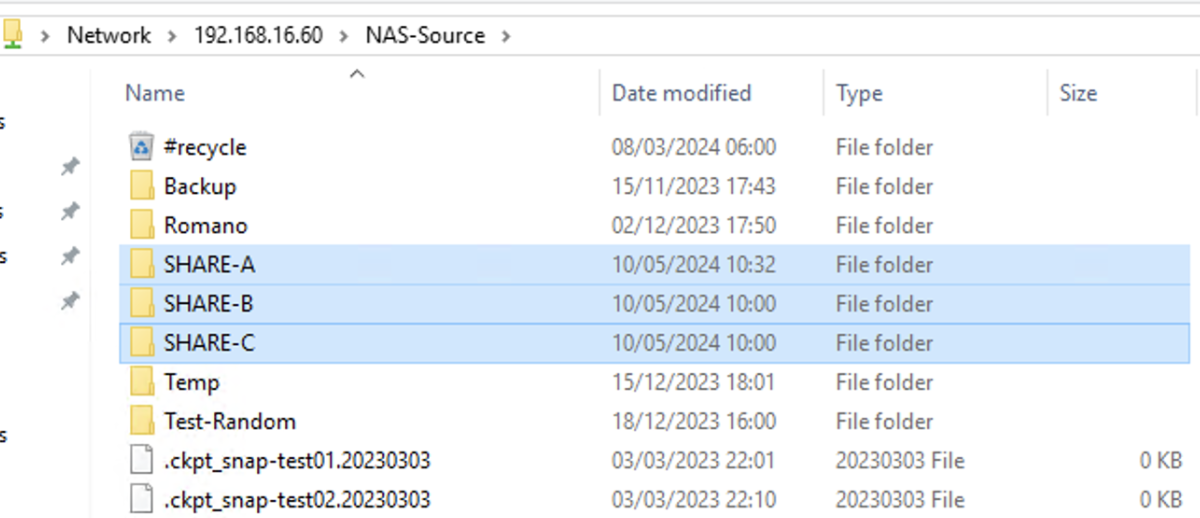
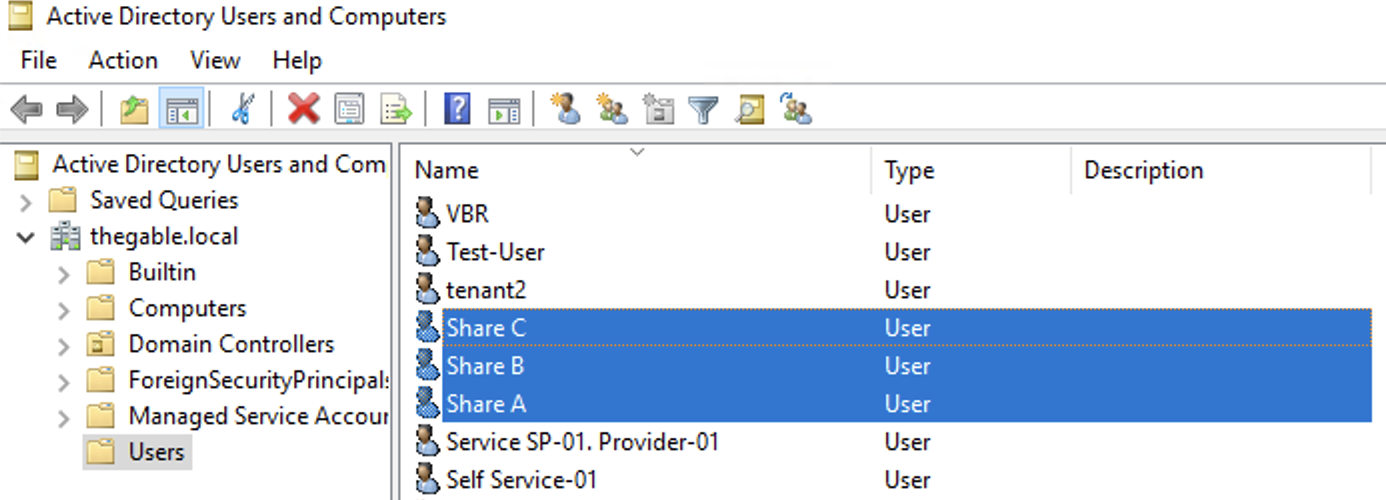 Immagine 2
Immagine 2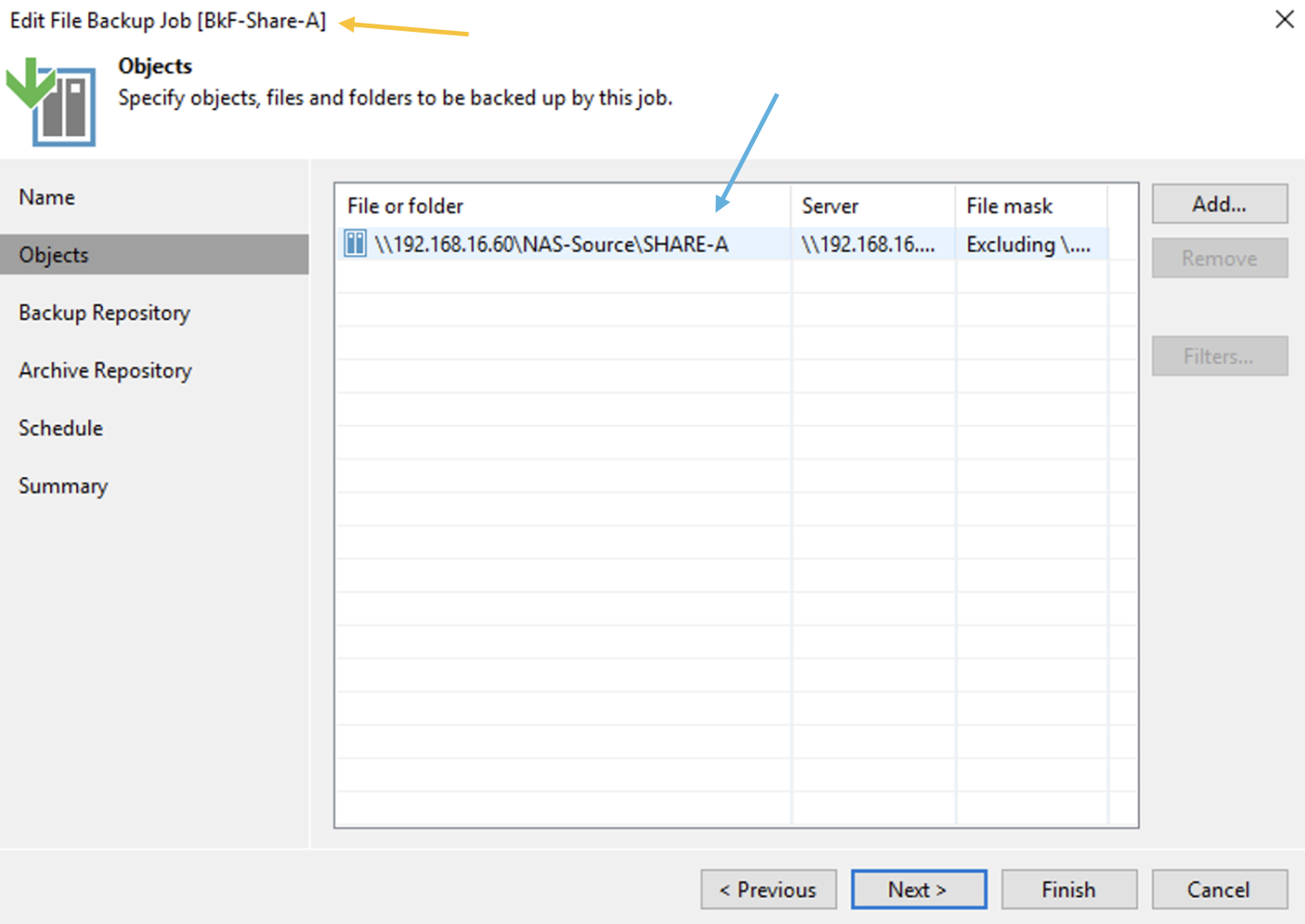 Immagine 3
Immagine 3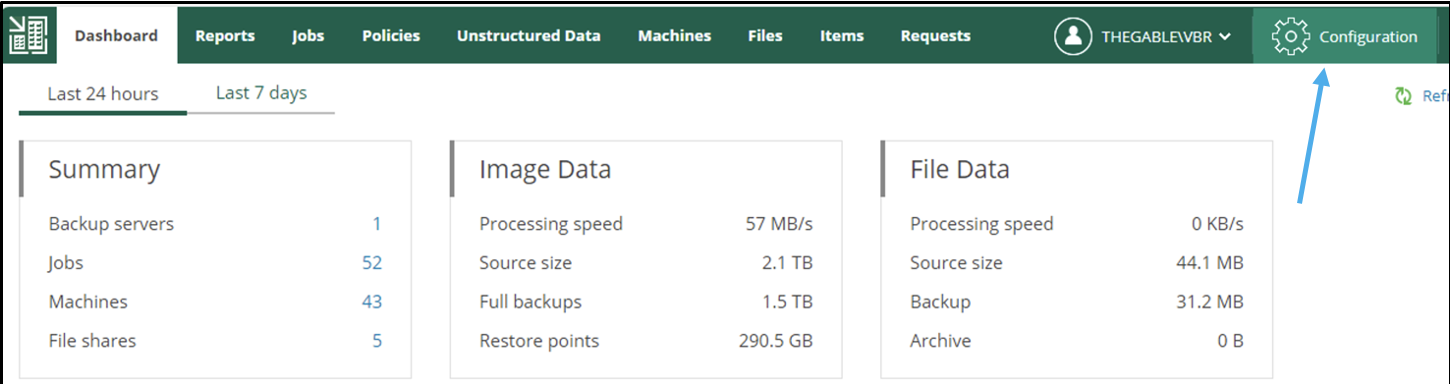 Immagine 4
Immagine 4 Immagine 5
Immagine 5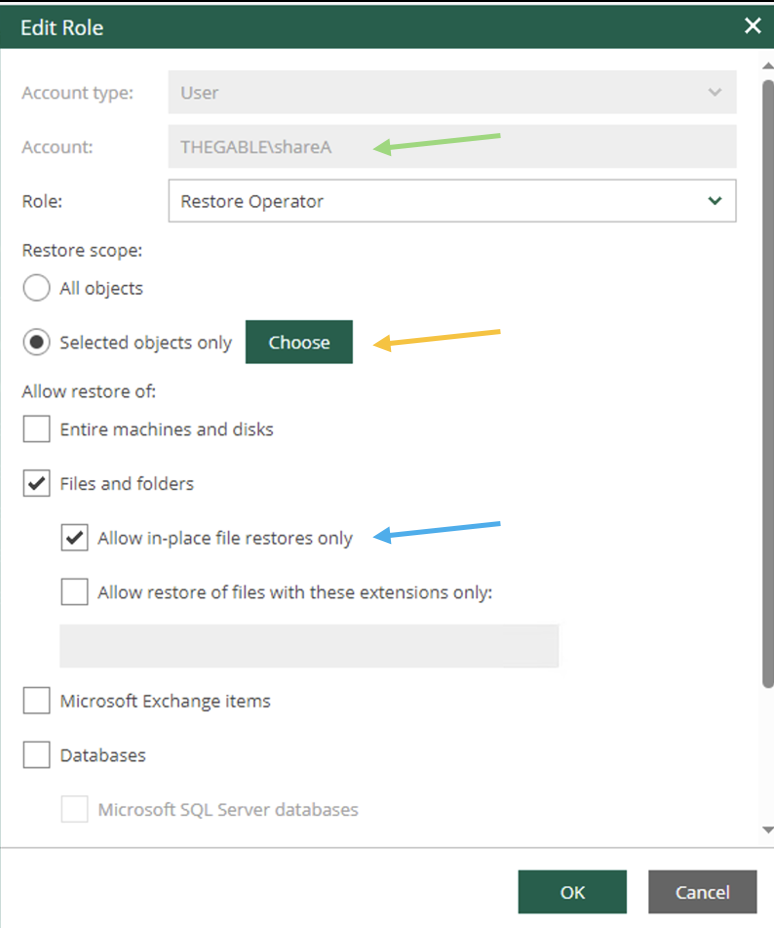 Immagine 6
Immagine 6 immagine 7
immagine 7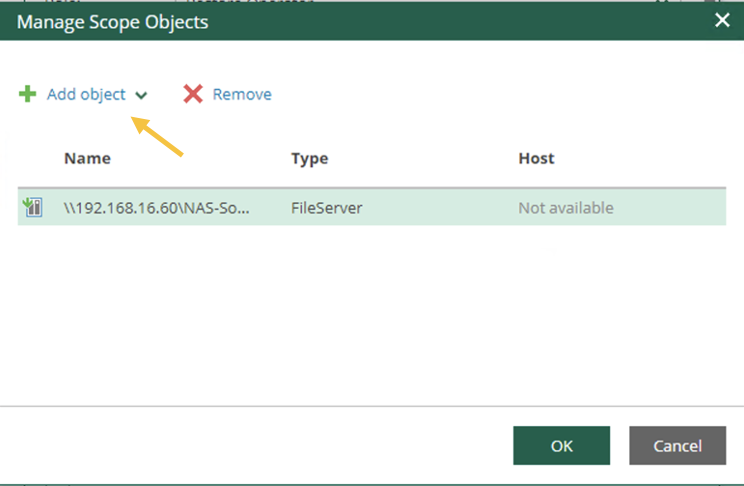 Immagine 8
Immagine 8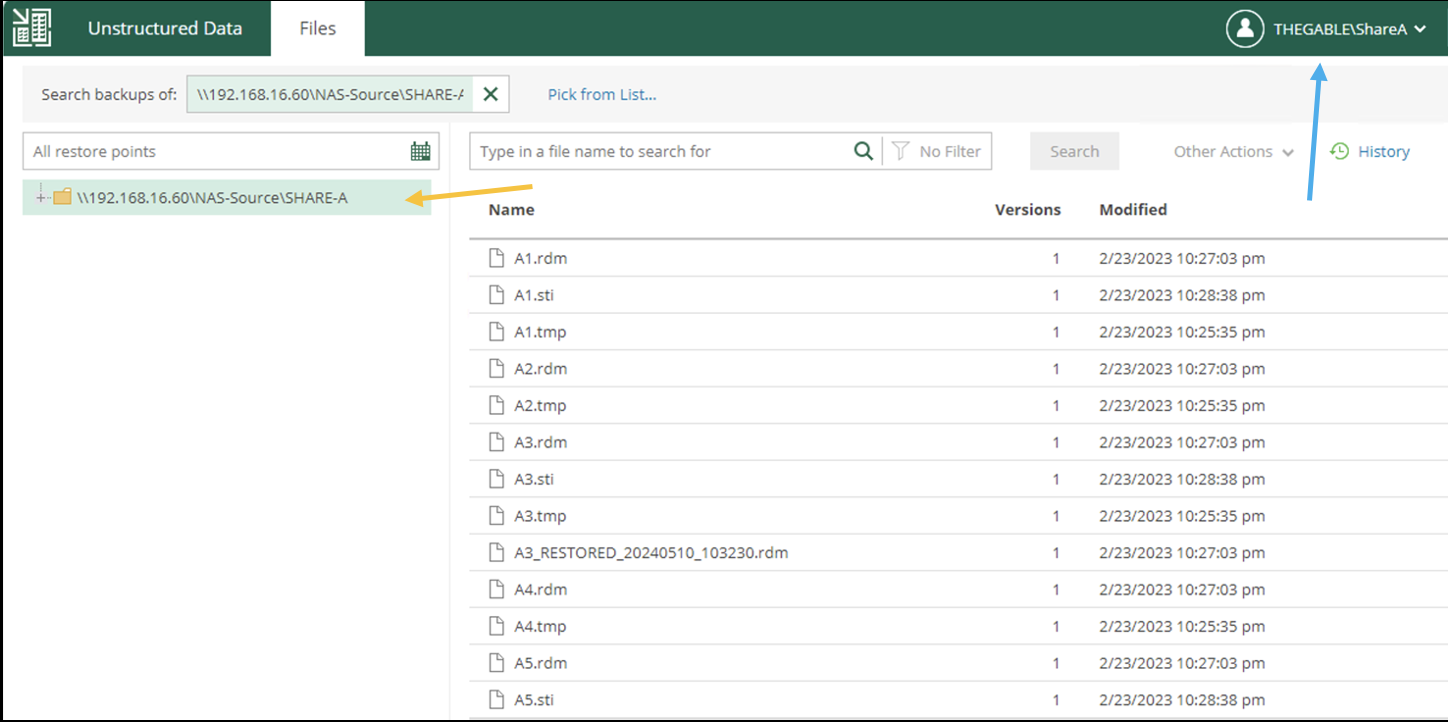 Immagine 9
Immagine 9